- Mixture model
-
See also: Mixture distribution
In statistics, a mixture model is a probabilistic model for representing the presence of sub-populations within an overall population, without requiring that an observed data-set should identify the sub-population to which an individual observation belongs. Formally a mixture model corresponds to the mixture distribution that represents the probability distribution of observations in the overall population. However, while problems associated with "mixture distributions" relate to deriving the properties of the overall population from those of the sub-populations, "mixture models" are used to make statistical inferences about the properties of the sub-populations given only observations on the pooled population, without sub-population-identity information.
Some ways of implementing mixture models involve steps that do attribute postulated sub-population-identities to individual observations (or weights towards such sub-populations), in which case these can be regarded as a types of unsupervised learning or clustering procedures. However not all inference procedures involve such steps.
Mixture models should not be confused with model for compositional data, i.e., data whose components are constrained to sum to a constant value (1, 100%, etc.).
Contents
Structure of a mixture model
General mixture model
A typical finite-dimensional mixture model is a hierarchical model consisting of the following components:
- N random variables corresponding to observations, each assumed to be distributed according to a mixture of K components, with each component belonging to the same parametric family of distributions but with different parameters
- N corresponding random latent variables specifying the identity of the mixture component of each observation, each distributed according to a K-dimensional categorical distribution
- A set of K mixture weights, each of which is a probability (a real number between 0 and 1), all of which sum to 1
- A set of K parameters, each specifying the parameter of the corresponding mixture component. In many cases, each "parameter" is actually a set of parameters. For example, observations distributed according to a mixture of one-dimensional Gaussian distributions will have a mean and variance for each component. Observations distributed according to a mixture of V-dimensional categorical distributions (e.g., when each observation is a word from a vocabulary of size V) will have a vector of V probabilities, collectively summing to 1.
In addition, in a Bayesian setting, the mixture weights and parameters will themselves be random variables, and prior distributions will be placed over the variables. In such a case, the weights are typically viewed as a K-dimensional random vector drawn from a Dirichlet distribution (the conjugate prior of the categorical distribution), and the parameters will be distributed according to their respective conjugate priors.
Mathematically, a basic parametric mixture model can be described as follows:
In a Bayesian setting, all parameters are associated with random variables, as follows:
This characterization uses F and H to describe arbitrary distributions over observations and parameters, respectively. Typically H will be the conjugate prior of F. The two most common choices of F are Gaussian aka "normal" (for real-valued observations) and categorical (for discrete observations). Other common possibilities for the distribution of the mixture components are:
- Binomial distribution, for the number of "positive occurrences" (e.g., successes, yes votes, etc.) given a fixed number of total occurrences
- Multinomial distribution, similar to the binomial distribution, but for counts of multi-way occurrences (e.g., yes/no/maybe in a survey)
- Negative binomial distribution, for binomial-type observations but where the quantity of interest is the number of failures before a given number of successes occurs
- Poisson distribution, for the number of occurrences of an event in a given period of time, for an event that is characterized by a fixed rate of occurrence
- Exponential distribution, for the time before the next event occurs, for an event that is characterized by a fixed rate of occurrence
- Log-normal distribution, for positive real numbers that are assumed to grow exponentially, such as incomes or prices
- Multivariate normal distribution (aka multivariate Gaussian distribution), for vectors of correlated outcomes that are individually Gaussian-distributed
- A vector of Bernoulli-distributed values, corresponding, e.g., to a black-and-white image, with each value representing a pixel; see the handwriting-recognition example below
Specific examples
A typical non-Bayesian Gaussian mixture model looks like this:
A Bayesian version of a Gaussian mixture model is as follows:
A typical non-Bayesian mixture model with categorical observations looks like this:
A typical Bayesian mixture model with categorical observations looks like this:
Examples
A financial model
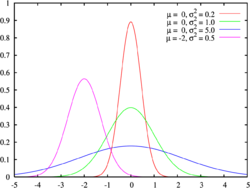 The normal distribution is plotted using different means and variances
The normal distribution is plotted using different means and variances
Financial returns often behave differently in normal situations and during crisis times. A mixture model [1] for return data seems reasonable. Some model this as a jump-diffusion model, or as a mixture of two normal distributions.
House prices
Assume that we observe the prices of N different houses. Different types of houses in different neighborhoods will have vastly different prices, but the price of a particular type of house in a particular neighborhood (e.g., three-bedroom house in moderately-upscale neighborhood) will tend to cluster fairly closely around the mean. One possible model of such prices would be to assume that the prices are accurately described by a mixture model with K different components, each distributed as a normal distribution with unknown mean and variance, with each component specifying a particular combination of house type/neighborhood. Fitting this model to observed prices, e.g., using the expectation-maximization algorithm, would tend to cluster the prices according to house type/neighborhood and reveal the spread of prices in each type/neighborhood. (Note that for values such as prices or incomes that are guaranteed to be positive and which tend to grow exponentially, a log-normal distribution might actually be a better model than a normal distribution.)
Topics in a document
Assume that a document is composed of N different words from a total vocabulary of size V, where each word corresponds to one of K possible topics. The distribution of such words could be modeled as a mixture of K different V-dimensional categorical distributions. A model of this sort is commonly termed a topic model. Note that expectation maximization applied to such a model will typically fail to produce realistic results, due (among other things) to the excessive number of parameters. Some sorts of additional assumptions are typically necessary to get good results. Typically two sorts of additional components are added to the model:
- A prior distribution is placed over the parameters describing the topic distributions, using a Dirichlet distribution with a concentration parameter that is set significantly below 1, so as to encourage sparse distributions (where only a small number of words have significantly non-zero probabilities).
- Some sort of additional constraint is placed over the topic identities of words, to take advantage of natural clustering.
-
- For example, a Markov chain could be placed on the topic identities (i.e., the latent variables specifying the mixture component of each observation), corresponding to the fact that nearby words belong to similar topics. (This results in a hidden Markov model, specifically one where a prior distribution is placed over state transitions that favors transitions that stay in the same state.)
- Another possibility is the latent Dirichlet allocation model, which divides up the words into D different documents and assumes that in each document only a small number of topics occur with any frequency.
Handwriting recognition
The following example is based on an example in Christopher M. Bishop, Pattern Recognition and Machine Learning.[2]
Imagine that we are given an N×N black-and-white image that is known to be a scan of a hand-written digit between 0 and 9, but we don't know which digit is written. We can create a mixture model with K = 10 different components, where each component is a vector of size N2 of Bernoulli distributions (one per pixel). Such a model can be trained with the expectation-maximization algorithm on an unlabeled set of hand-written digits, and will effectively cluster the images according to the digit being written. The same model could then be used to recognize the digit of another image simply by holding the parameters constant, computing the probability of the new image for each possible digit (a trivial calculation), and returning the digit that generated the highest probability.
Direct and indirect applications
The financial example above is one direct application of the mixture model, a situation in which we assume an underlying mechanism so that each observation belongs to one of some number of different sources or categories. This underlying mechanism may or may not, however, be observable. In this form of mixture, each of the sources is described by a component probability density function, and its mixture weight is the probability that an observation comes from this component.
In an indirect application of the mixture model we do not assume such a mechanism. The mixture model is simply used for its mathematical flexibilities. For example, a mixture of two normal distributions with different means may result in a density with two modes, which is not modeled by standard parametric distributions. Another example is given by the possibility of mixture distributions to model fatter tails than the basic Gaussian ones, so as to be a candidate for modeling more extreme events. When combined with dynamical consistency, this approach has been applied to financial derivatives valuation in presence of the volatility smile in the context of local volatility models.
Identifiability
Identifiability refers to the existence of a unique characterization for any one of the models in the class being considered. Estimation procedure may not be well-defined and asymptotic theory may not hold if a model is not identifiable.
Example
Let J be the class of all binomial distributions with n = 2. Then a mixture of two members of J would have
- p0 = π(1 − θ1)2 + (1 − π)(1 − θ2)2
- p1 = 2πθ1(1 − θ1) + 2(1 − π)θ2(1 − θ2)
and p2 = 1 − p0 − p1. Clearly, given p0 and p1, it is not possible to determine the above mixture model uniquely, as there are three parameters (π, θ1, θ2) to be determined.
Definition
Consider a mixture of parametric distributions of the same class. Let
be the class of all component distributions. Then the convex hull K of J defines the class of all finite mixture of distributions in J:
K is said to be identifiable if all its members are unique, that is, given two members p and p′ in K, being mixtures of k distributions and k′ distributions respectively in J, we have p = p′ if and only if, first of all, k = k′ and secondly we can reorder the summations such that ai = ai′ and ƒi = ƒi′ for all i.
Parameter estimation and system identification
Parametric mixture models are often used when we know the distribution Y and we can sample from X, but we would like to determine the ai and θi values. Such situations can arise in studies in which we sample from a population that is composed of several distinct subpopulations.
It is common to think of probability mixture modeling as a missing data problem. One way to understand this is to assume that the data points under consideration have "membership" in one of the distributions we are using to model the data. When we start, this membership is unknown, or missing. The job of estimation is to devise appropriate parameters for the model functions we choose, with the connection to the data points being represented as their membership in the individual model distributions.
A variety of approaches to the problem of mixture decomposition have been proposed, many of which focus on maximum likelihood methods such as expectation maximization (EM) or maximum a posteriori estimation (MAP). Generally these methods consider separately the question of parameter estimation and system identification, that is to say a distinction is made between the determination of the number and functional form of components within a mixture and the estimation of the corresponding parameter values. Some notable departures are the graphical methods as outlined in Tarter and Lock [3] and more recently minimum message length (MML) techniques such as Figueiredo and Jain [4] and to some extent the moment matching pattern analysis routines suggested by McWilliam and Loh (2009).[5]
Expectation maximization (EM)
Expectation maximization (EM) is seemingly the most popular technique used to determine the parameters of a mixture with an a priori given number of components. This is a particular way of implementing maximum likelihood estimation for this problem. EM is of particular appeal for finite normal mixtures where closed-form expressions are possible such as in the following iterative algorithm by Dempster et al. (1977)
with the posterior probabilities
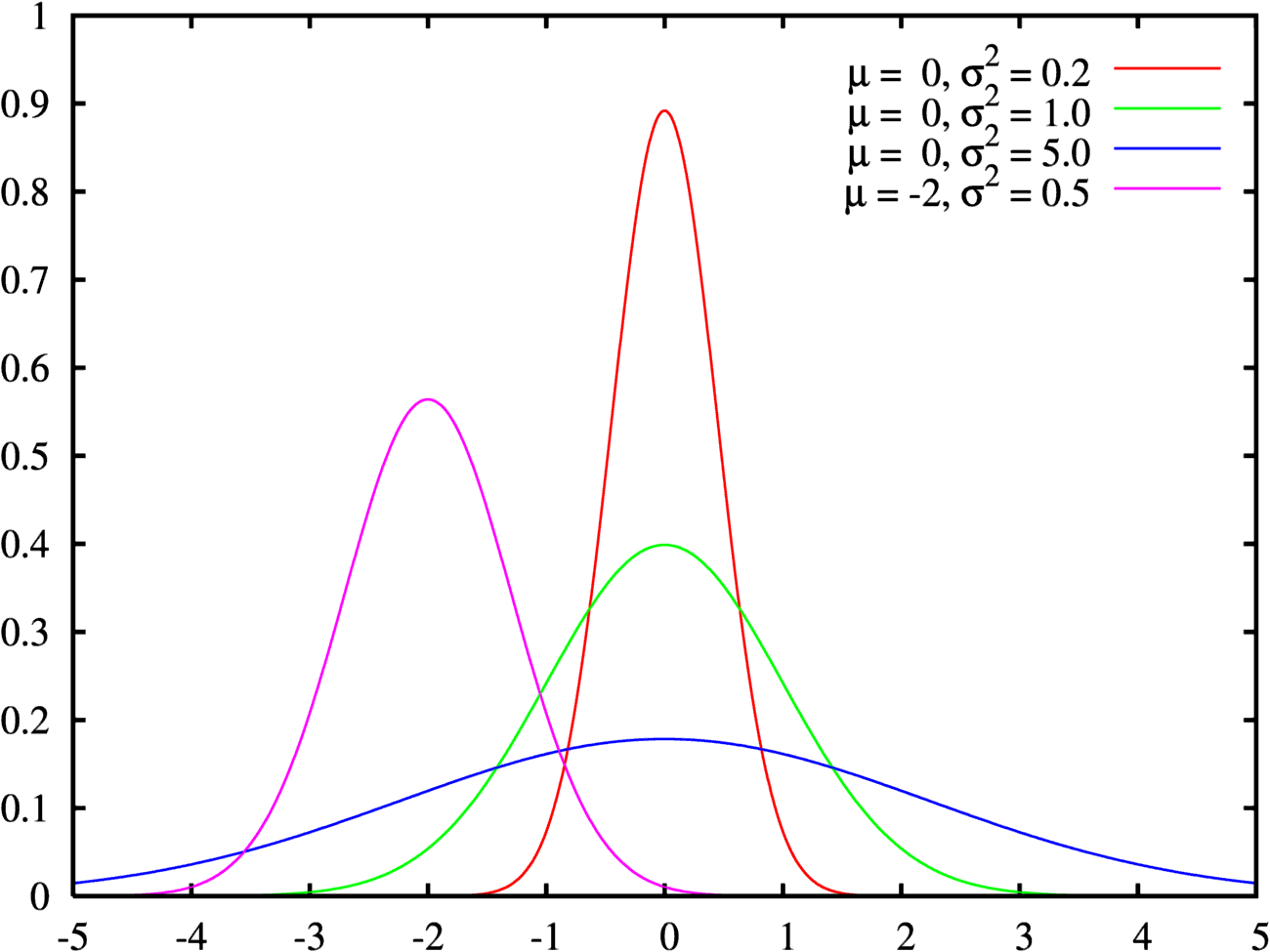
Thus on the basis of the current estimate for the parameters, the conditional probability a given observation x(t) being generated from state s is determined for each t = 1, …, m ; m being the sample size. The parameters are then updated such that the new component weights correspond to the average conditional probability and each component mean and covariance is the component specific weighted average of the mean and covariance of the entire sample.
Dempster[citation needed] also showed that each successive EM iteration will not decrease the likelihood, a property not shared by other gradient based maximization techniques. Moreover EM naturally embeds within it constraints on the probability vector, and for sufficiently large sample sizes positive definiteness of the covariance iterates. This is a key advantage since explicitly constrained methods incur extra computational costs to check and maintain appropriate values. Theoretically EM is a first-order algorithm and as such converges slowly to a fixed-point solution. Redner and Walker (1984)[Full citation needed] make this point arguing in favour of superlinear and second order Newton and quasi-Newton methods and reporting slow convergence in EM on the basis of their empirical tests. They do concede that convergence in likelihood was rapid even if convergence in the parameter values themselves was not. The relative merits of EM and other algorithms vis-à-vis convergence have been discussed in other literature.[6]
Other common objections to the use of EM are that it has a propensity to spuriously identify local maximisers,[7] as well as displaying sensitivity to initial values.[citation needed] One may address these problems by evaluating EM at several initial points in the parameter space but this is computationally costly and other approaches, such as the annealing EM method of Udea and Nakano (1998) (in which the initial components are essentially forced to overlap, providing a less heterogeneous basis for initial guesses), may be preferable.
Figueiredo and Jain [4] note that convergence to 'meaningless' parameter values obtained at the boundary (where regularity conditions breakdown, e.g., Ghosh and Sen (1985)) is frequently observed when the number of model components exceeds the optimal/true one. On this basis they suggest a unified approach to estimation and identification in which the initial n is chosen to greatly exceed the expected optimal value. Their optimization routine is constructed via a minimum message length (MML) criterion that effectively eliminates a candidate component if there is insufficient information to support it. In this way it is possible to systematize reductions in n and consider estimation and identification jointly.
The Expectation-maximization algorithm can be used to compute the parameters of a parametric mixture model distribution (the ais and θis). It is an iterative algorithm with two steps: an expectation step and a maximization step. Practical examples of EM and Mixture Modeling are included in the SOCR demonstrations.
The expectation step
With initial guesses for the parameters of our mixture model, "partial membership" of each data point in each constituent distribution is computed by calculating expectation values for the membership variables of each data point. That is, for each data point xj and distribution Yi, the membership value yi, j is:
The maximization step
With expectation values in hand for group membership, plug-in estimates are recomputed for the distribution parameters.
The mixing coefficients ai are the means of the membership values over the N data points.
The component model parameters θi are also calculated by expectation maximization using data points xj that have been weighted using the membership values. For example, if θ is a mean μ
With new estimates for ai and the θi's, the expectation step is repeated to recompute new membership values. The entire procedure is repeated until model parameters converge.
Markov chain Monte Carlo
As an alternative to the EM algorithm, the mixture model parameters can be deduced using posterior sampling as indicated by Bayes' theorem. This is still regarded as an incomplete data problem whereby membership of data points is the missing data. A two-step iterative procedure known as Gibbs sampling can be used.
The previous example of a mixture of two Gaussian distributions can demonstrate how the method works. As before, initial guesses of the parameters for the mixture model are made. Instead of computing partial memberships for each elemental distribution, a membership value for each data point is drawn from a Bernoulli distribution (that is, it will be assigned to either the first or the second Gaussian). The Bernoulli parameter θ is determined for each data point on the basis of one of the constituent distributions.[vague] Draws from the distribution generate membership associations for each data point. Plug-in estimators can then be used as in the M step of EM to generate a new set of mixture model parameters, and the binomial draw step repeated.
Moment matching
The method of moment matching is one of the oldest techniques for determining the mixture parameters dating back to Karl Pearson’s seminal work of 1894. In this approach the parameters of the mixture are determined such that the composite distribution has moments matching some given value. In many instances extraction of solutions to the moment equations may present non-trivial algebraic or computational problems. Moreover numerical analysis by Day [8] has indicated that such methods may be inefficient compared to EM. Nonetheless there has been renewed interest in this method, e.g., Craigmile and Titterington (1998) and Wang.[9]
McWilliam and Loh (2009) consider the characterisation of a hyper-cuboid normal mixture copula in large dimensional systems for which EM would be computationally prohibitive. Here a pattern analysis routine is used to generate multivariate tail-dependencies consistent with a set of univariate and (in some sense) bivariate moments. The performance of this method is then evaluated using equity log-return data with Kolmogorov-Smirnov test statistics suggesting a good descriptive fit.
The EF3M algorithm
The EM algorithm searches for the parameter estimates that maximize the posterior conditional distribution function of the entire sample. This means that higher moments for which the researcher may have no theoretical interpretation or confidence (typically beyond the 4th moment) are impacting the parameter estimates, thus moving away from the solution that exactly fits parameters on which the modeler has greater confidence and theoretical understanding.
Lopez de Prado (2011)[10] developed an algorithm, called EF3M, which presents the advantage of exactly fitting the first 3 moments, for which estimate the researcher typically has some degree of confidence or theoretical interpretation. The 4th moments is not exactly matched, due to its sampling error, although it guides the convergence of the mixing probability. Finally, the 5th moment is only used to assess the goodness of the fit when alternative solutions exist.
This author argues that a number of reasons would make EF3M preferable to ML or EM algorithms:
- Researchers usually have greater confidence in the first 3 or 4 moments of the distribution than on higher moments or the overall sample.)[11] An exact match of the 4th and particularly 5th moment is not always desirable due to their significant sampling errors, which are correlated to the magnitude of those moments. Biasing the mixture's estimates in order to accommodate even higher (and therefore noisier) moments, as the ML and EM-based algorithms do, is far from ideal.
- In the Quantitative Finance literature, it is the first 4 moments that play a key role in the theoretical modeling of risk and portfolio optimization, not the 5th and beyond.
- In the context of simulation, a standard problem is the modeling of a distribution that exactly matches the empirically observed first 3 or 4 moments.
- EM algorithms are computationally intensive as a function of the sample size and tend to get trapped on local minima. Speed, and therefore simplicity, is a critical concern, considering that datasets nowadays often exceed hundreds of millions of observations.
Spectral method
Some problems in mixture model estimation can be solved using spectral methods. In particular it becomes useful if data points xi are points in high-dimensional Euclidean space, and the hidden distributions are known to be log-concave (such as Gaussian distribution or Exponential distribution).
Spectral methods of learning mixture models are based on the use of Singular Value Decomposition of a matrix which contains data points. The idea is to consider the top k singular vectors, where k is the number of distributions to be learned. The projection of each data point to a linear subspace spanned by those vectors groups points originating from the same distribution very close together, while points from different distributions stay far apart.
One distinctive feature of the spectral method is that it allows us to prove that if distributions satisfy certain separation condition (e.g., not too close), then the estimated mixture will be very close to the true one with high probability.
Graphical Methods
Tarter and Lock [3] describe a graphical approach to mixture identification in which a kernel function is applied to an empirical frequency plot so to reduce intra-component variance. In this way one may more readily identify components having differing means. While this λ-method does not require prior knowledge of the number or functional form of the components its success does rely on the choice of the kernel parameters which to some extent implicitly embeds assumptions about the component structure.
Other methods
Some of them can even probably learn mixtures of heavy-tailed distributions including those with infinite variance (see links to papers below). In this setting, EM based methods would not work, since the Expectation step would diverge due to presence of outliers.
A simulation
To simulate a sample of size N that is from a mixture of distributions Fi, i= = 1= to= n, with probabilities pi (sum= pi = 1):
- Generate N random numbers from a categorical distribution of size n and probabilities pi for i= 1= to n. These tell you which of the Fi each of the N values will come from. Denote by mi the quantity of random numbers assigned to the ith category.
- For each i, generate mi random numbers from the Fi distribution.
Extensions
In a Bayesian setting, additional levels can be added to the graphical model defining the mixture model. For example, in the common latent Dirichlet allocation topic model, the observations are sets of words drawn from D different documents and the K mixture components represent topics that are shared across documents. Each document has a different set of mixture weights, which specify the topics prevalent in that document. All sets of mixture weights share common hyperparameters.
A very common extension is to connect the latent variables defining the mixture component identities into a Markov chain, instead of assuming that they are independent identically distributed random variables. The resulting model is termed a hidden Markov model and is one of the most common sequential hierarchical models. Numerous extensions of hidden Markov models have been developed; see the resulting article for more information.
History
Mixture distributions and the problem of mixture decomposition, that is the identification of its constituent components and the parameters thereof, has been cited in the literature as far back as 1846 (Quetelet in McLaughlan ,[7] 2000) although common reference is made to the work of Karl Pearson (1894)[citation needed] as the first author to explicitly address the decomposition problem in characterising non-normal attributes of forehead to body length ratios in female shore crab populations. The motivation for this work was provided by the zoologist Walter Frank Raphael Weldon who had speculated in 1893 (in Tarter and Lock[3]) that asymmetry in the histogram of these ratios could signal evolutionary divergence. Pearson’s approach was to fit a univariate mixture of two normals to the data by choosing the five parameters of the mixture such that the empirical moments matched that of the model.
While his work was successful in identifying two potentially distinct sub-populations and in demonstrating the flexibility of mixtures as a moment matching tool, the formulation required the solution of a 9th degree (nonic) polynomial which at the time posed a significant computational challenge.
Subsequent works focused on addressing these problems, but it was not until the advent of the modern computer and the popularisation of Maximum Likelihood (ML) parameterisation techniques that research really took off.[12] Since that time there has been a vast body of research on the subject spanning areas such as Fisheries research, Agriculture, Botany, Economics, Medicine, Genetics, Psychology, Palaeontology, Electrophoresis, Finance, Sedimentology/Geology and Zoology.[13]
See also
Mixture
Hierarchical models
Outlier detection
References
- ^ Dinov, ID. "Expectation Maximization and Mixture Modeling Tutorial". California Digital Library, Statistics Online Computational Resource, Paper EM_MM, http://repositories.cdlib.org/socr/EM_MM, December 9, 2008
- ^ Bishop, Christopher (2006). Pattern recognition and machine learning. New York: Springer. ISBN 9780387310732.
- ^ a b c Michael E. Tarter (1993), Model Free Curve Estimation, Chapman and Hall
- ^ a b M. A. T. Figueiredo and A. K. Jain (2002), "Unsupervised Learning of Finite Mixture Models", IEEE Transactions on Pattern Analysis and Machine Intelligence 24: 381–396
- ^ N. McWilliam, K. Loh (2008), Incorporating Multidimensional Tail-Dependencies in the Valuation of Credit Derivatives (Working Paper) [1]
- ^ L. Xu and M. I. Jordan (1996), "On Convergence Properties of the EM Algorithm for Gaussian Mixtures", Neural Computation 8: 129–151
- ^ a b G. J. McLaughlan (2000), Finite Mixture Models, Wiley
- ^ N. E. Day (1969), "Estimating the components of a mixture of two normal distributions", Biometrika 56: 463–474
- ^ J. Wang (2001), "Generating daily changes in market variables using a multivariate mixture of normal distributions", Proceedings of the 33rd winter conference on simulation,IEEE Computer Society: 283–289
- ^ Lopez de Prado, M. (2011): "Exact Fit for a Mixture of Two Gaussians: The EF3M Algorithm", The Social Science Research Network. Available at http://ssrn.com/abstract=1931734
- ^ Lopez de Prado, M. (2008): "The Sharpe Ratio Efficient Frontier", The Social Science Research Network. Available at http://ssrn.com/abstract=1821643
- ^ G. J. McLaughlan (1988), Mixture Models: inference and applications to clustering, Dekker
- ^ Titterington et al (1985)
Further reading
Books on mixture models
- Everitt, B.S. and Hand D.J. (1981) "Finite mixture distributions", Chapman & Hall. ISBN 0412224208
- Lindsay B.G. (1995) "Mixture Models: Theory, Geometry, and Applications". NSF-CBMS Regional Conference Series in Probability and Statistics, Vol. 5, Institute of Mathematical Statistics, Hayward.
- Marin, J.M., Mengersen, K. and Robert, C.P. "Bayesian modelling and inference on mixtures of distributions". Handbook of Statistics 25, D. Dey and C.R. Rao (eds). Elsevier-Sciences (to appear). available as PDF
- McLachlan, G.J. and Basford, K.E. (1988) "Mixture Models: Inference and Applications to Clustering", Marcel Dekker. ISBN 9780824776916
- McLachlan, G.J. and Peel, D. (2000) Finite Mixture Models, Wiley. ISBN 0471006262
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). "Section 16.1. Gaussian Mixture Models and k-Means Clustering". Numerical Recipes: The Art of Scientific Computing (3rd ed.). New York: Cambridge University Press. ISBN 978-0-521-88068-8. http://apps.nrbook.com/empanel/index.html#pg=842.
- Titterington, D., A. Smith, and U. Makov (1985) "Statistical Analysis of Finite Mixture Distributions," John Wiley & Sons. ISBN 0471907634
Application of Gaussian mixture models
- D.A. Reynolds and R.C. Rose (1995). "Robust text-independent speaker identification using Gaussianmixture speaker models". IEEE Transactions on Speech and Audio Processing. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=365379.
- H. Permuter, J. Francos and I.H. Jermyn (2003). "Gaussian mixture models of texture and colour for image database retrieval". IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings (ICASSP '03). http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1199538.
- Wolfgang Lemke (2005). Term Structure Modeling and Estimation in a State Space Framework. Springer Verlag. ISBN 978-3540283423.
- Damiano Brigo and Fabio Mercurio (2001). "Displaced and Mixture Diffusions for Analytically-Tractable Smile Models". Mathematical Finance - Bachelier Congress 2000. Proceedings. Springer Verlag.
- Damiano Brigo and Fabio Mercurio (2002). "Lognormal-mixture dynamics and calibration to market volatility smiles". International Journal of Theoretical and Applied Finance 5 (4).
- Carol Alexander (2004). "Normal mixture diffusion with uncertain volatility: Modelling short- and long-term smile effects". Journal of Banking & Finance 28 (12).
- Yannis Stylianou, Yannis Pantazis, Felipe Calderero, Pedro Larroy, Francois Severin, Sascha Schimke, Rolando Bonal, Federico Matta, and Athanasios Valsamakis (2005). "GMM-Based Multimodal Biometric Verification". http://www.enterface.net/enterface05/docs/results/reports/project5.pdf.
External links
- The SOCR demonstrations of EM and Mixture Modeling
- Mixture modelling page (and the Snob program for Minimum Message Length (MML) applied to finite mixture models), maintained by D.L. Dowe.
- PyMix - Python Mixture Package, algorithms and data structures for a broad variety of mixture model based data mining applications in Python
- scikits.learn.mixture.GMM - A Python package for learning Gaussian Mixture Models (and sampling from them), previously packaged with SciPy and now packaged as a SciKit
- GMM.m Matlab code for GMM Implementation
- GPUmix C++ implementation of Bayesian Mixture Models using EM and MCMC with 100x speed acceleration using GPGPU.
- [2] Matlab code for GMM Implementation using EM algorithm
- [3] jMEF: A Java open source library for learning and processing mixtures of exponential families (using duality with Bregman divergences). Include a Matlab wrapper.
Categories:- Statistical models
- Cluster analysis
- Latent variable models
- Probabilistic models
- Machine learning










![\Sigma_s^{(j+1)} = \frac{\sum_{t =1}^N h_s^{(j)}(t) [x^{(t)}-\mu_s^{(j)}][x^{(t)}-\mu_s^{(j)}]^{\top}}{\sum_{t =1}^N h_s^{(j)}(t)}](3/a73440880b409fcc9ba7b7ae19a0e8c1.png)




Wikimedia Foundation. 2010.