- Level of detail
-
In computer graphics, accounting for level of detail involves decreasing the complexity of a 3D object representation as it moves away from the viewer or according other metrics such as object importance, eye-space speed or position. Level of detail techniques increases the efficiency of rendering by decreasing the workload on graphics pipeline stages, usually vertex transformations. The reduced visual quality of the model is often unnoticed because of the small effect on object appearance when distant or moving fast.
Although most of the time LOD is applied to geometry detail only, the basic concept can be generalized. Recently, LOD techniques included also shader management to keep control of pixel complexity. A form of level of detail management has been applied to textures for years, under the name of mipmapping, also providing higher rendering quality.
It is commonplace to say that "an object has been LOD'd" when the object is simplified by the underlying LOD-ing algorithm.
Contents
Historical reference
The origin[1] of all the LoD algorithms for 3D computer graphics can be traced back to an article by James H. Clark in the October 1976 issue of Communications of the ACM. At the time, computers were monolithic and rare, and graphics was being driven by researchers. The hardware itself was completely different, both architecturally and performance-wise. As such, many differences could be observed with regard to today's algorithms but also many common points.
The original algorithm presented a much more generic approach to what will be discussed here. After introducing some available algorithms for geometry management, it is stated that most fruitful gains came from "...structuring the environments being rendered", allowing to exploit faster transformations and clipping operations.
The same environment structuring is now proposed as a way to control varying detail thus avoiding unnecessary computations, yet delivering adequate visual quality:
“ For example, a dodecahedron looks like a sphere from a sufficiently large distance and thus can be used to model it so long as it is viewed from that or a greater distance. However, if it must ever be viewed more closely, it will look like a dodecahedron. One solution to this is simply to define it with the most detail that will ever be necessary. However, then it might have far more detail than is needed to represent it at large distances, and in a complex environment with many such objects, there would be too many polygons (or other geometric primitives) for the visible surface algorithms to efficiently handle. ” The proposed algorithm envisions a tree data structure which encodes in its arcs both transformations and transitions to more detailed objects. In this way, each node encodes an object and according to a fast heuristic, the tree is descended to the leafs which provide each object with more detail. When a leaf is reached, other methods could be used when higher detail is needed, such as Catmull's recursive subdivision[2].
“ The significant point, however, is that in a complex environment, the amount of information presented about the various objects in the environment varies according to the fraction of the field of view occupied by those objects. ” The paper then introduces clipping (not to be confused with culling (computer graphics), although often similar), various considerations on the graphical working set and its impact on performance, interactions between the proposed algorithm and others to improve rendering speed. Interested readers are encouraged in checking the references for further details on the topic.
Well known approaches
Although the algorithm introduced above covers a whole range of level of detail management techniques, real world applications usually employ different methods according the information being rendered. Because of the appearance of the considered objects, two main algorithm families are used.
The first is based on subdividing the space in a finite amount of regions, each with a certain level of detail. The result is discrete amount of detail levels, from which the name Discrete LoD (DLOD). There's no way to support a smooth transition between LOD levels at this level, although alpha blending or morphing can be used to avoid visual popping.
The latter considers the polygon mesh being rendered as a function which must be evaluated requiring to avoid excessive errors which are a function of some heuristic (usually distance) themselves. The given "mesh" function is then continuously evaluated and an optimized version is produced according to a tradeoff between visual quality and performance. Those kind of algorithms are usually referred as Continuous LOD (CLOD).
Details on Discrete LOD
 An example of various DLOD ranges. Darker areas are meant to be rendered with higher detail. An additional culling operation is run, discarding all the information outside the frustum (colored areas).
An example of various DLOD ranges. Darker areas are meant to be rendered with higher detail. An additional culling operation is run, discarding all the information outside the frustum (colored areas).
The basic concept of discrete LOD (DLOD) is to provide various models to represent the same object. Obtaining those models requires an external algorithm which is often non-trivial and subject of many polygon reduction techniques. Successive LOD-ing algorithms will simply assume those models are available.
DLOD algorithms are often used in performance-intensive applications with small data sets which can easily fit in memory. Although out of core algorithms could be used, the information granularity is not well suited to this kind of application. This kind of algorithm is usually easier to get working, providing both faster performance and lower CPU usage because of the few operations involved.
DLOD methods are often used for "stand-alone" moving objects, possibly including complex animation methods. A different approach is used for geomipmapping [3], a popular terrain rendering algorithm because this applies to terrain meshes which are both graphically and topologically different from "object" meshes. Instead of computing an error and simplify the mesh according to this, geomipmapping takes a fixed reduction method, evaluates the error introduced and computes a distance at which the error is acceptable. Although straightforward, the algorithm provides decent performance.
A discrete LOD example
As a simple example, consider the following sphere. A discrete LOD approach would cache a certain number of models to be used at different distances. Because the model can trivially be procedurally generated by its mathematical formulation, using a different amount of sample points distributed on the surface is sufficient to generate the various models required. This pass is not a LOD-ing algorithm.
Visual impact comparisons and measurements Image 

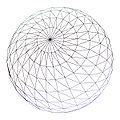
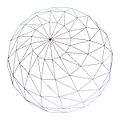

Vertices ~5500 ~2880 ~1580 ~670 140 Notes Maximum detail,
for closeups.Minimum detail,
very far objects.To simulate a realistic transform bound scenario, we'll use an ad-hoc written application. We'll make sure we're not CPU bound by using simple algorithms and minimum fragment operations. Each frame, the program will compute each sphere's distance and choose a model from a pool according to this information. To easily show the concept, the distance at which each model is used is hard coded in the source. A more involved method would compute adequate models according to the usage distance chosen.
We use OpenGL for rendering because its high efficiency in managing small batches, storing each model in a display list thus avoiding communication overheads. Additional vertex load is given by applying two directional light sources ideally located infinitely far away.
The following table compares the performance of LoD aware rendering and a full detail (brute force) method.
Visual impact comparisons and measurements Brute DLOD Comparison Rendered
images


Render time 27.27 ms 1.29 ms 21 × reduction Scene vertices
(thousands)2328.48 109.44 21 × reduction Hierarchical LOD
Because hardware is geared towards large amounts of detail, rendering low polygon objects may score sub-optimal performances. HLOD avoids the problem by grouping different objects together[4]. This allows for higher efficiency as well as taking advantage of proximity considerations.
See also
- MeshLab an open source mesh processing tool that is able to accurately simplify 3D polygonal meshes.
- Polygon Cruncher
- Simplygon
- Vizup
- Rational Reducer
- Pro Optimizer
References
- ^ Communications of the ACM, October 1976 Volume 19 Number 10. Pages 547-554. Hierarchical Geometric Models for Visible Surface Algorithms by James H. Clark, University of California at Santa Cruz. Digitalized scan is freely available at http://accad.osu.edu/~waynec/history/PDFs/clark-vis-surface.pdf.
- ^ Catmull E., A Subdivision Algorithm for Computer Display of Curved Surfaces. Tech. Rep. UTEC-CSc-74-133, University of Utah, Salt Lake City, Utah, Dec. 1974.
- ^ de Boer, W.H., Fast Terrain Rendering using Geometrical Mipmapping, in flipCode featured articles, October 2000. Available at http://www.flipcode.com/tutorials/tut_geomipmaps.shtml.
- ^ Carl Erikson's paper at http://www.cs.unc.edu/Research/ProjectSummaries/hlods.pdf provides a quick, yet effective overlook at HLOD mechanisms. A more involved description follows in his thesis, at https://wwwx.cs.unc.edu/~geom/papers/documents/dissertations/erikson00.pdf.
Categories:








Wikimedia Foundation. 2010.