- Consistent estimator
-
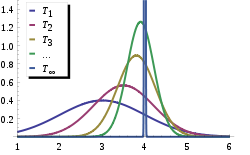 {T1, T2, T3, …} is a sequence of estimators for parameter θ0, the true value of which is 4. This sequence is consistent: the estimators are getting more and more concentrated near the true value θ0; at the same time, these estimators are biased. The limiting distribution of the sequence is a degenerate random variable which equals θ0 with probability 1.
{T1, T2, T3, …} is a sequence of estimators for parameter θ0, the true value of which is 4. This sequence is consistent: the estimators are getting more and more concentrated near the true value θ0; at the same time, these estimators are biased. The limiting distribution of the sequence is a degenerate random variable which equals θ0 with probability 1.
In statistics, a sequence of estimators for parameter θ0 is said to be consistent (or asymptotically consistent) if this sequence converges in probability to θ0. It means that the distributions of the estimators become more and more concentrated near the true value of the parameter being estimated, so that the probability of the estimator being arbitrarily close to θ0 converges to one.
In practice one usually constructs a single estimator as a function of an available sample of size n, and then imagines being able to keep collecting data and expanding the sample ad infinitum. In this way one would obtain a sequence of estimators indexed by n and the notion of consistency will be understood as the sample size “grows to infinity”. If this sequence converges in probability to the true value θ0, we call it a consistent estimator; otherwise the estimator is said to be inconsistent.
The consistency as defined here is sometimes referred to as the weak consistency. When we replace the convergence in probability with the almost sure convergence, then the sequence of estimators is said to be strongly consistent.
Contents
Definition
Loosely speaking, an estimator Tn of parameter θ is said to be consistent, if it converges in probability to the true value of the parameter:[1]
A more rigorous definition takes into account the fact that θ is actually unknown, and thus the convergence in probability must take place for every possible value of this parameter. Suppose {pθ: θ ∈ Θ} is a family of distributions (the parametric model), and Xθ = {X1, X2, … : Xi ~ pθ} is an infinite sample from the distribution pθ. Let { Tn(Xθ) } be a sequence of estimators for some parameter g(θ). Usually Tn will be based on the first n observations of a sample. Then this sequence {Tn} is said to be (weakly) consistent if [2]
This definition uses g(θ) instead of simply θ, because often one is interested in estimating a certain function or a sub-vector of the underlying parameter. In the next example we estimate the location parameter of the model, but not the scale:
Example: sample mean for normal random variables
Suppose one has a sequence of observations {X1, X2, …} from a normal N(μ, σ2) distribution. To estimate μ based on the first n observations, we use the sample mean: Tn = (X1 + … + Xn)/n. This defines a sequence of estimators, indexed by the sample size n.
From the properties of the normal distribution, we know that Tn is itself normally distributed, with mean μ and variance σ2/n. Equivalently,
 has a standard normal distribution. Then
has a standard normal distribution. Thenas n tends to infinity, for any fixed ε > 0. Therefore, the sequence Tn of sample means is consistent for the population mean μ.
Establishing consistency
The notion of asymptotic consistency is very close, almost synonymous to the notion of convergence in probability. As such, any theorem, lemma, or property which establishes convergence in probability may be used to prove the consistency. Many such tools exist:
- In order to demonstrate consistency directly from the definition one can use the inequality [3]
the most common choice for function h being either the absolute value (in which case it is known as Markov inequality), or the quadratic function (respectively Chebychev's inequality).
- Another useful result is the continuous mapping theorem: if Tn is consistent for θ and g(·) is a real-valued function continuous at point θ, then g(Tn) will be consistent for g(θ):[4]
- Slutsky’s theorem can be used to combine several different estimators, or an estimator with a non-random covergent sequence. If Tn →pα, and Sn →pβ, then [5]
- If estimator Tn is given by an explicit formula, then most likely the formula will employ sums of random variables, and then the law of large numbers can be used: for a sequence {Xn} of random variables and under suitable conditions,
- If estimator Tn is defined implicitly, for example as a value that maximizes certain objective function (see extremum estimator), then a more complicated argument involving stochastic equicontinuity has to be used.[6]
Bias versus consistency
Unbiased but not consistent
An estimator can be unbiased but not consistent. For example, for an iid sample {x
1,..., x
n} one can use T(X) = x
1 as the estimator of the mean E[x]. This estimator is obviously unbiased, and obviously inconsistent.Biased but consistent
Alternatively, an estimator can be biased but consistent. For example if the mean is estimated by
 it is biased, but as
it is biased, but as  , it approaches the correct value, and so it is consistent.
, it approaches the correct value, and so it is consistent.See also
- Fisher consistency — alternative, although rarely used concept of consistency for the estimators
- Consistent test — the notion of consistency in the context of hypothesis testing
Notes
- ^ Amemiya 1985, Definition 3.4.2
- ^ Lehman & Casella 1998, p. 332
- ^ Amemiya 1985, equation (3.2.5)
- ^ Amemiya 1985, Theorem 3.2.6
- ^ Amemiya 1985, Theorem 3.2.7
- ^ Newey & McFadden (1994, Chapter 2)
References
- Amemiya, Takeshi (1985). Advanced econometrics. Harvard University Press. ISBN 0-674-00560-0.
- Lehmann, E. L.; Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer. ISBN 0-387-98502-6.
- Newey, W.; McFadden, D. (1994). Large sample estimation and hypothesis testing. In “Handbook of Econometrics”, Vol. 4, Ch. 36. Elsevier Science. ISBN 0-444-88766-0.
- Nikulin, M.S. (2001), "Consistent estimator", in Hazewinkel, Michiel, Encyclopaedia of Mathematics, Springer, ISBN 978-1556080104, http://eom.springer.de/C/c025240.htm
Categories:- Statistical theory
- Statistical inference
- Estimation theory
- Asymptotic statistical theory



![\Pr\!\left[\,|T_n-\mu|\geq\varepsilon\,\right] =
\Pr\!\left[ \frac{\sqrt{n}\,\big|T_n-\mu\big|}{\sigma} \geq \sqrt{n}\varepsilon/\sigma \right] =
2\left(1-\Phi\left(\frac{\sqrt{n}\,\varepsilon}{\sigma}\right)\right) \to 0](9/5c92cefb19a45c611988853110d55675.png)
![\Pr\!\big[h(T_n-\theta)\geq\varepsilon\big] \leq \frac{\operatorname{E}\big[h(T_n-\theta)\big]}{\varepsilon},](7/4f7aa32dba161e2fa74245d4bb24dac9.png)


![\frac{1}{n}\sum_{i=1}^n g(X_i) \ \xrightarrow{p}\ \operatorname{E}[\,g(X)\,]](9/de96989f2dd508a4ea2e9dc554029171.png)
Wikimedia Foundation. 2010.