- Genetic code
-
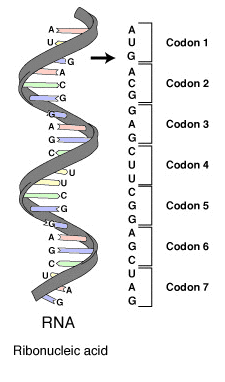
 A series of codons in part of a messenger RNA (mRNA) molecule. Each codon consists of three nucleotides, usually representing a single amino acid. The nucleotides are abbreviated with the letters A, U, G and C. This is mRNA, which uses U (uracil). DNA uses T (thymine) instead. This mRNA molecule will instruct a ribosome to synthesize a protein according to this code.
A series of codons in part of a messenger RNA (mRNA) molecule. Each codon consists of three nucleotides, usually representing a single amino acid. The nucleotides are abbreviated with the letters A, U, G and C. This is mRNA, which uses U (uracil). DNA uses T (thymine) instead. This mRNA molecule will instruct a ribosome to synthesize a protein according to this code.
The genetic code is the set of rules by which information encoded in genetic material (DNA or mRNA sequences) is translated into proteins (amino acid sequences) by living cells.
The code defines how sequences of three nucleotides, called codons, specify which amino acid will be added next during protein synthesis. With some exceptions,[1] a three-nucleotide codon in a nucleic acid sequence specifies a single amino acid. Because the vast majority of genes are encoded with exactly the same code (see the RNA codon table), this particular code is often referred to as the canonical or standard genetic code, or simply the genetic code, though in fact there are many variant codes. For example, protein synthesis in human mitochondria relies on a genetic code that differs from the standard genetic code.
Not all genetic information is stored using the genetic code. All organisms' DNA contains regulatory sequences, intergenic segments, chromosomal structural areas, and other non-coding DNA that can contribute greatly to phenotype. Those elements operate under sets of rules that are distinct from the codon-to-amino acid paradigm underlying the genetic code.
Contents
Discovery
 The genetic code
The genetic codeAfter the structure of DNA was discovered by James Watson and Francis Crick, who used the experimental evidence of Maurice Wilkins and Rosalind Franklin (among others), serious efforts to understand the nature of the encoding of proteins began. George Gamow postulated that a three-letter code must be employed to encode the 20 standard amino acids used by living cells to encode proteins. With four different nucleotides, a code of 2 nucleotides could only code for a maximum of 42 or 16 amino acids. A code of 3 nucleotides could code for a maximum of 43 or 64 amino acids.[2]
The fact that codons consist of three DNA bases was first demonstrated in the Crick, Brenner et al. experiment. The first elucidation of a codon was done by Marshall Nirenberg and Heinrich J. Matthaei in 1961 at the National Institutes of Health. They used a cell-free system to translate a poly-uracil RNA sequence (i.e., UUUUU...) and discovered that the polypeptide that they had synthesized consisted of only the amino acid phenylalanine. They thereby deduced that the codon UUU specified the amino acid phenylalanine. This was followed by experiments in the laboratory of Severo Ochoa demonstrating that the poly-adenine RNA sequence (AAAAA...) coded for the polypeptide poly-lysine[3] and that the poly-cytosine RNA sequence (CCCCC...) coded for the polypeptide poly-proline.[4] Therefore the codon AAA specified the amino acid lysine, and the codon CCC specified the amino acid proline. Using different copolymers most of the remaining codons were then determined. Extending this work, Nirenberg and Philip Leder revealed the triplet nature of the genetic code and allowed the codons of the standard genetic code to be deciphered. In these experiments, various combinations of mRNA were passed through a filter that contained ribosomes, the components of cells that translate RNA into protein. Unique triplets promoted the binding of specific tRNAs to the ribosome. Leder and Nirenberg were able to determine the sequences of 54 out of 64 codons in their experiments.[5]
Subsequent work by Har Gobind Khorana identified the rest of the genetic code. Shortly after, Robert W. Holley determined the structure of transfer RNA (tRNA), the adapter molecule that facilitates the process of translating RNA into protein. This work was based upon earlier studies by Severo Ochoa, who received the Nobel prize in 1959 for his work on the enzymology of RNA synthesis.[6] In 1968, Khorana, Holley and Nirenberg received the Nobel Prize in Physiology or Medicine for their work.[7]
Transfer of information via the genetic code
The genome of an organism is inscribed in DNA, or, in the case of some viruses, RNA. The portion of the genome that codes for a protein or an RNA is called a gene. Those genes that code for proteins are composed of tri-nucleotide units called codons, each coding for a single amino acid. Each nucleotide sub-unit consists of a phosphate, a deoxyribose sugar, and one of the four nitrogenous nucleobases. The purine bases adenine (A) and guanine (G) are larger and consist of two aromatic rings. The pyrimidine bases cytosine (C) and thymine (T) are smaller and consist of only one aromatic ring. In the double-helix configuration, two strands of DNA are joined to each other by hydrogen bonds in an arrangement known as base pairing. These bonds almost always form between an adenine base on one strand and a thymine base on the other strand, or between a cytosine base on one strand and a guanine base on the other. This means that the number of A and T bases will be the same in a given double helix, as will the number of G and C bases.[8]:102–117 In RNA, thymine (T) is replaced by uracil (U), and the deoxyribose is substituted by ribose.[8]:127
Each protein-coding gene is transcribed into a molecule of the related polymer RNA. In prokaryotes, this RNA functions as messenger RNA or mRNA; in eukaryotes, the transcript needs to be processed to produce a mature mRNA. The mRNA is, in turn, translated on the ribosome into an amino acid chain or polypeptide.[8]:Chp 12 The process of translation requires transfer RNAs specific for individual amino acids with the amino acids covalently attached to them, guanosine triphosphate as an energy source, and a number of translation factors. tRNAs have anticodons complementary to the codons in mRNA and can be "charged" covalently with amino acids at their 3' terminal CCA ends. Individual tRNAs are charged with specific amino acids by enzymes known as aminoacyl tRNA synthetases, which have high specificity for both their cognate amino acids and tRNAs. The high specificity of these enzymes is a major reason why the fidelity of protein translation is maintained.[8]:464–469
There are 4³ = 64 different codon combinations possible with a triplet codon of three nucleotides; all 64 codons are assigned for either amino acids or stop signals during translation. If, for example, an RNA sequence UUUAAACCC is considered and the reading frame starts with the first U (by convention, 5' to 3'), there are three codons, namely, UUU, AAA, and CCC, each of which specifies one amino acid. This RNA sequence will be translated into an amino acid sequence, three amino acids long.[8]:521–539 A given amino acid may be encoded by between one and six different codon sequences. A comparison may be made with computer science, where the codon is similar to a word, which is the standard "chunk" for handling data (like one amino acid of a protein), and a nucleotide is similar to a bit, in that it is the smallest unit.
The standard genetic code is shown in the following tables. Table 1 shows what amino acid each of the 64 codons specifies. Table 2 shows what codons specify each of the 20 standard amino acids involved in translation. These are called forward and reverse codon tables, respectively. For example, the codon AAU represents the amino acid asparagine, and UGU and UGC represent cysteine (standard three-letter designations, Asn and Cys, respectively).[8]:522
RNA codon table
nonpolar polar basic acidic (stop codon) 2nd base U C A G 1st base U UUU (Phe/F) Phenylalanine UCU (Ser/S) Serine UAU (Tyr/Y) Tyrosine UGU (Cys/C) Cysteine UUC (Phe/F) Phenylalanine UCC (Ser/S) Serine UAC (Tyr/Y) Tyrosine UGC (Cys/C) Cysteine UUA (Leu/L) Leucine UCA (Ser/S) Serine UAA Stop (Ochre) UGA Stop (Opal) UUG (Leu/L) Leucine UCG (Ser/S) Serine UAG Stop (Amber) UGG (Trp/W) Tryptophan C CUU (Leu/L) Leucine CCU (Pro/P) Proline CAU (His/H) Histidine CGU (Arg/R) Arginine CUC (Leu/L) Leucine CCC (Pro/P) Proline CAC (His/H) Histidine CGC (Arg/R) Arginine CUA (Leu/L) Leucine CCA (Pro/P) Proline CAA (Gln/Q) Glutamine CGA (Arg/R) Arginine CUG (Leu/L) Leucine CCG (Pro/P) Proline CAG (Gln/Q) Glutamine CGG (Arg/R) Arginine A AUU (Ile/I) Isoleucine ACU (Thr/T) Threonine AAU (Asn/N) Asparagine AGU (Ser/S) Serine AUC (Ile/I) Isoleucine ACC (Thr/T) Threonine AAC (Asn/N) Asparagine AGC (Ser/S) Serine AUA (Ile/I) Isoleucine ACA (Thr/T) Threonine AAA (Lys/K) Lysine AGA (Arg/R) Arginine AUG[A] (Met/M) Methionine ACG (Thr/T) Threonine AAG (Lys/K) Lysine AGG (Arg/R) Arginine G GUU (Val/V) Valine GCU (Ala/A) Alanine GAU (Asp/D) Aspartic acid GGU (Gly/G) Glycine GUC (Val/V) Valine GCC (Ala/A) Alanine GAC (Asp/D) Aspartic acid GGC (Gly/G) Glycine GUA (Val/V) Valine GCA (Ala/A) Alanine GAA (Glu/E) Glutamic acid GGA (Gly/G) Glycine GUG (Val/V) Valine GCG (Ala/A) Alanine GAG (Glu/E) Glutamic acid GGG (Gly/G) Glycine - A The codon AUG both codes for methionine and serves as an initiation site: the first AUG in an mRNA's coding region is where translation into protein begins.[9]
Inverse table Ala/A GCU, GCC, GCA, GCG Leu/L UUA, UUG, CUU, CUC, CUA, CUG Arg/R CGU, CGC, CGA, CGG, AGA, AGG Lys/K AAA, AAG Asn/N AAU, AAC Met/M AUG Asp/D GAU, GAC Phe/F UUU, UUC Cys/C UGU, UGC Pro/P CCU, CCC, CCA, CCG Gln/Q CAA, CAG Ser/S UCU, UCC, UCA, UCG, AGU, AGC Glu/E GAA, GAG Thr/T ACU, ACC, ACA, ACG Gly/G GGU, GGC, GGA, GGG Trp/W UGG His/H CAU, CAC Tyr/Y UAU, UAC Ile/I AUU, AUC, AUA Val/V GUU, GUC, GUA, GUG START AUG STOP UAA, UGA, UAG DNA codon table
Main article: DNA codon tableThe DNA codon table is essentially identical to that for RNA, but with U replaced by T.
Salient features
Sequence reading frame
A codon is defined by the initial nucleotide from which translation starts. For example, the string GGGAAACCC, if read from the first position, contains the codons GGG, AAA, and CCC; and, if read from the second position, it contains the codons GGA and AAC; if read starting from the third position, GAA and ACC. Every sequence can, thus, be read in three reading frames, each of which will produce a different amino acid sequence (in the given example, Gly-Lys-Pro, Gly-Asn, or Glu-Thr, respectively). With double-stranded DNA, there are six possible reading frames, three in the forward orientation on one strand and three reverse on the opposite strand.[10]:330 The actual frame in which a protein sequence is translated is defined by a start codon, usually the first AUG codon in the mRNA sequence.
Start/stop codons
Translation starts with a chain initiation codon (start codon). Unlike stop codons, the codon alone is not sufficient to begin the process. Nearby sequences (such as the Shine-Dalgarno sequence in E. coli) and initiation factors are also required to start translation. The most common start codon is AUG, which is read as methionine or, in bacteria, as formylmethionine. Alternative start codons (depending on the organism), include "GUG" or "UUG"; these codons normally represent valine and leucine, respectively, but, as a start codon, they are translated as methionine or formylmethionine.[11]
The three stop codons have been given names: UAG is amber, UGA is opal (sometimes also called umber), and UAA is ochre. "Amber" was named by discoverers Richard Epstein and Charles Steinberg after their friend Harris Bernstein, whose last name means "amber" in German. The other two stop codons were named "ochre" and "opal" in order to keep the "color names" theme. Stop codons are also called "termination" or "nonsense" codons. They signal release of the nascent polypeptide from the ribosome because there is no cognate tRNA that has anticodons complementary to these stop signals, and so a release factor binds to the ribosome instead.[12]
Effect of mutations
During the process of DNA replication, errors occasionally occur in the polymerization of the second strand. These errors, called mutations, can have an impact on the phenotype of an organism, especially if they occur within the protein coding sequence of a gene. Error rates are usually very low—1 error in every 10–100 million bases—due to the "proofreading" ability of DNA polymerases.[14][15]
Missense mutations and nonsense mutations are examples of point mutations, which can cause genetic diseases such as sickle-cell disease and thalassemia respectively.[16][17][18] Clinically important missense mutations generally change the properties of the coded amino acid residue between being basic, acidic polar or non-polar, whereas nonsense mutations result in a stop codon.[10]:266
Mutations that disrupt the reading frame sequence by indels (insertions or deletions) of a non-multiple of 3 nucleotide bases are known as frameshift mutations. These mutations usually result in a completely different translation from the original, and are also very likely to cause a stop codon to be read, which truncates the creation of the protein.[19] These mutations may impair the function of the resulting protein, and are thus rare in in vivo protein-coding sequences. One reason inheritance of frameshift mutations is rare is that, if the protein being translated is essential for growth under the selective pressures the organism faces, absence of a functional protein may cause death before the organism is viable.[20] Frameshift mutations may result in severe genetic diseases such as Tay-Sachs disease.[21]
Although most mutations that change protein sequences are harmful or neutral, some mutations have a positive effect on an organism.[22] These mutations may enable the mutant organism to withstand particular environmental stresses better than wild-type organisms, or reproduce more quickly. In these cases a mutation will tend to become more common in a population through natural selection.[23] Viruses that use RNA as their genetic material have rapid mutation rates,[24] which can be an advantage, since these viruses will evolve constantly and rapidly, and thus evade the defensive responses of e.g. the human immune system.[25] In large populations of asexually reproducing organisms, for example, E. coli, multiple beneficial mutations may co-occur. This phenomenon is called clonal interference and causes competition among the mutations.[26]
Degeneracy
Degeneracy is the redundancy of the genetic code. The genetic code has redundancy but no ambiguity (see the codon tables above for the full correlation). For example, although codons GAA and GAG both specify glutamic acid (redundancy), neither of them specifies any other amino acid (no ambiguity). The codons encoding one amino acid may differ in any of their three positions. For example the amino acid glutamic acid is specified by GAA and GAG codons (difference in the third position), the amino acid leucine is specified by UUA, UUG, CUU, CUC, CUA, CUG codons (difference in the first or third position), while the amino acid serine is specified by UCA, UCG, UCC, UCU, AGU, AGC (difference in the first, second, or third position).[8]:521–522
A position of a codon is said to be a fourfold degenerate site if any nucleotide at this position specifies the same amino acid. For example, the third position of the glycine codons (GGA, GGG, GGC, GGU) is a fourfold degenerate site, because all nucleotide substitutions at this site are synonymous; i.e., they do not change the amino acid. Only the third positions of some codons may be fourfold degenerate.[8]:521–522 A position of a codon is said to be a twofold degenerate site if only two of four possible nucleotides at this position specify the same amino acid. For example, the third position of the glutamic acid codons (GAA, GAG) is a twofold degenerate site. In twofold degenerate sites, the equivalent nucleotides are always either two purines (A/G) or two pyrimidines (C/U), so only transversional substitutions (purine to pyrimidine or pyrimidine to purine) in twofold degenerate sites are nonsynonymous.[8]:521–522 A position of a codon is said to be a non-degenerate site if any mutation at this position results in amino acid substitution. There is only one threefold degenerate site where changing to three of the four nucleotides may have no effect on the amino acid (depending on what it is changed to), while changing to the fourth possible nucleotide always results in an amino acid substitution. This is the third position of an isoleucine codon: AUU, AUC, or AUA all encode isoleucine, but AUG encodes methionine. In computation this position is often treated as a twofold degenerate site.[8]:521–522
There are three amino acids encoded by six different codons: serine, leucine, and arginine. Only two amino acids are specified by a single codon. One of these is the amino-acid methionine, specified by the codon AUG, which also specifies the start of translation; the other is tryptophan, specified by the codon UGG. The degeneracy of the genetic code is what accounts for the existence of synonymous mutations.[8]:Chp 15
Degeneracy results because there are more codons than encodable amino acids. For example, if there were two bases per codon, then only 16 amino acids could be coded for (4²=16). Because at least 21 codes are required (20 amino acids plus stop) and the next largest number of bases is three, then 4³ gives 64 possible codons, meaning that some degeneracy must exist.[8]:521–522
These properties of the genetic code make it more fault-tolerant for point mutations. For example, in theory, fourfold degenerate codons can tolerate any point mutation at the third position, although codon usage bias restricts this in practice in many organisms; twofold degenerate codons can tolerate one out of the three possible point mutations at the third position. Since transition mutations (purine to purine or pyrimidine to pyrimidine mutations) are more likely than transversion (purine to pyrimidine or vice-versa) mutations, the equivalence of purines or that of pyrimidines at twofold degenerate sites adds a further fault-tolerance.[8]:531–532
 Grouping of codons by amino acid residue molar volume and hydropathy.
Grouping of codons by amino acid residue molar volume and hydropathy.A practical consequence of redundancy is that some errors in the genetic code cause only a silent mutation or an error that would not affect the protein because the hydrophilicity or hydrophobicity is maintained by equivalent substitution of amino acids; for example, a codon of NUN (where N = any nucleotide) tends to code for hydrophobic amino acids. NCN yields amino acid residues that are small in size and moderate in hydropathy; NAN encodes average size hydrophilic residues.[27][28] These tendencies may result from the shared ancestry of the aminoacyl tRNA synthetases related to these codons.
Despite the redundancy of the genetic code, single-point mutations can still cause dysfunctional proteins. For example, a mutated hemoglobin gene causes sickle-cell disease. In the mutant hemoglobin, a hydrophilic glutamate (Glu) is substituted by the hydrophobic valine (Val); that is, GAA or GAG becomes GUA or GUG. The substitution of glutamate by valine reduces the solubility of β-globin, which causes hemoglobin to form linear polymers linked by the hydrophobic interaction between the valine groups, causing sickle-cell deformation of erythrocytes. In general, sickle-cell disease is not caused by a de novo mutation. It is, rather, selected for in geographic regions where malaria is common (in a way similar to thalassemia), as heterozygous people have some resistance to the malarial Plasmodium parasite (heterozygote advantage).[29]
These variable codes for amino acids are allowed because of modified bases in the first base of the anticodon of the tRNA, and the base-pair formed is called a wobble base pair. The modified bases include inosine and the Non-Watson-Crick U-G basepair.[30]
Variations to the standard genetic code
While slight variations on the standard code had been predicted earlier,[31] none were discovered until 1979, when researchers studying human mitochondrial genes discovered they used an alternative code. Many slight variants have been discovered since then,[32] including various alternative mitochondrial codes,[33] and small variants such as translation of the codon UGA as tryptophan in the species Mycoplasma and translation of CUG as a serine rather than a leucine in some members of the genus Candida (see the article on Candida albicans).[34][35] In bacteria and archaea, GUG and UUG are common start codons, but in rare cases, certain proteins may use alternative start codons not normally used by that species.[32]
In certain proteins, non-standard amino acids are substituted for standard stop codons, depending on associated signal sequences in the messenger RNA. For example, UGA can code for selenocysteine, and UAG can code for pyrrolysine. Selenocysteine is now viewed as the 21st amino acid, and pyrrolysine is viewed as the 22nd.[32]
Despite these differences, all known naturally-occurring codes are very similar to each other, and the coding mechanism is the same for all organisms: three-base codons, tRNA, ribosomes, reading the code in the same direction and translating the code three letters at a time into sequences of amino acids.
Expanded genetic code
Main article: Expanded genetic codeSee also: Nucleic acid analoguesSince 2001, 40 non-natural amino acids have been added into protein by creating a unique codon (recoding) and a corresponding transfer-RNA:aminoacyl – tRNA-synthetase pair to encode it with diverse physicochemical and biological properties in order to be used as a tool to exploring protein structure and function or to create novel or enhanced proteins.[36][37]
H. Murakami and M. Sisido have extended some codons to have four and five bases. Steven A. Benner constructed a functional 65th (in vivo) codon.[38]
Origin
Despite the minor variations that exist, the genetic code used by all known forms of life is nearly universal. However, there is a huge number of possible genetic codes. If amino acids are randomly associated with triplet codons, there will be 1.5 x 1084 possible genetic codes.[39]:163
Phylogenetic analysis of transfer RNA suggests that tRNA molecules evolved before the present set of aminoacyl-tRNA synthetases.[40]
In theory, the genetic code could be completely random (a "frozen accident"), completely non-random (optimal) or a combination of random and nonrandom. There are enough data to refute the first possibility.[41] For a start, a quick view on the table of the genetic code shows a clustering of amino acid assignments. Furthermore, amino acids that share the same biosynthetic pathway tend to have the same first base in their codons,[42] and amino acids with similar physical properties tend to have similar codons.[43][44]
There are four themes running through the many theories about the evolution of the genetic code (and hence the origin of these patterns):[45]
- Chemical principles govern specific RNA interaction with amino acids. Experiments with aptamers showed that some amino acids have a selective chemical affinity for the base triplets that code for them.[46] Recent experiments show that of the 8 amino acids tested, 6 show some RNA triplet-amino acid association.[47][39]:170 This has been called the stereochemical code. The stereochemical code could have created an ancient core of assignments. The current complex translation mechanism involving tRNA and associated enzymes may be a later development, and maybe protein sequences were directly templated on base sequences.
- Biosynthetic expansion. The standard modern genetic code grew from a simpler earlier code through a process of "biosynthetic expansion". Here the idea is that primordial life "discovered" new amino acids (for example, as by-products of metabolism) and later incorporated some of these into the machinery of genetic coding. Although much circumstantial evidence has been found to suggest that fewer different amino acids were used in the past than today,[48] precise and detailed hypotheses about which amino acids entered the code in what order have proved far more controversial.[49][50]
- Natural selection has led to codon assignments of the genetic code that minimize the effects of mutations.[51] A recent hypothesis[52] suggests that the triplet code was derived from codes that used longer than triplet codons (such as quadruplet codons). Longer than triplet decoding would have higher degree of codon redundancy and would be more error resistant than the triplet decoding. This feature could allow accurate decoding in the absence of highly complex translational machinery such as the ribosome and prior to the time when cells began making ribosomes.
- Information channels: Information-theoretic approaches see the genetic code as an error-prone information channel.[53] The inherent noise (that is, errors) in the channel poses the organism with a fundamental question: how to construct a genetic code that can withstand the impact of noise[54] while accurately and efficiently translating information? These “rate-distortion” models[55] suggest that the genetic code originated as a result of the interplay of the three conflicting evolutionary forces: the needs for diverse amino-acids,[56] for error-tolerance[51] and for minimal cost of resources. The code emerges at a coding transition when the mapping of codons to amino-acids becomes nonrandom. The emergence of the code is governed by the topology defined by the probable errors and is related to the map coloring problem.[57]
See also
- DNA
- Genotype
- Human Genome Project
- Mutation
- Nucleobases
- Phenotype
- Proteins
References
- ^ Turanov AA, Lobanov AV, Fomenko DE, Morrison HG, Sogin ML, Klobutcher LA, Hatfield DL, Gladyshev VN (January 2009). "Genetic code supports targeted insertion of two amino acids by one codon". Science 323 (5911): 259–61. doi:10.1126/science.1164748. PMID 19131629.
- ^ Crick, Francis (1988). "Chapter 8: The genetic code". What mad pursuit: a personal view of scientific discovery. New York: Basic Books. pp. 89–101. ISBN 0-465-09138-5.
- ^ Gardner RS, Wahba AJ, Basilio C, Miller RS, Lengyel P, Speyer JF (December 1962). "Synthetic polynucleotides and the amino acid code. VII". Proc. Natl. Acad. Sci. U.S.A. 48 (12): 2087–94. doi:10.1073/pnas.48.12.2087. PMC 221128. PMID 13946552. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=221128.
- ^ Wahba AJ, Gardner RS, Basilio C, Miller RS, Speyer JF, Lengyel P (January 1963). "Synthetic polynucleotides and the amino acid code. VIII". Proc. Natl. Acad. Sci. U.S.A. 49: 116–22. doi:10.1073/pnas.49.1.116. PMC 300638. PMID 13998282. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=300638.
- ^ Nirenberg M, Leder P, Bernfield M, Brimacombe R, Trupin J, Rottman F, O'Neal C (May 1965). "RNA codewords and protein synthesis, VII. On the general nature of the RNA code". Proc. Natl. Acad. Sci. U.S.A. 53 (5): 1161–8. doi:10.1073/pnas.53.5.1161. PMC 301388. PMID 5330357. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=301388.
- ^ "The Nobel Prize in Physiology or Medicine 1959" (Press release). The Royal Swedish Academy of Science. 1959. http://nobelprize.org/nobel_prizes/medicine/laureates/1959/index.html. Retrieved 2010-02-27. "The Nobel Prize in Physiology or Medicine 1959 was awarded jointly to Severo Ochoa and Arthur Kornberg 'for their discovery of the mechanisms in the biological synthesis of ribonucleic acid and deoxyribonucleic acid'."
- ^ "The Nobel Prize in Physiology or Medicine 1968" (Press release). The Royal Swedish Academy of Science. 1968. http://nobelprize.org/nobel_prizes/medicine/laureates/1968/index.html. Retrieved 2010-02-27. "The Nobel Prize in Physiology or Medicine 1968 was awarded jointly to Robert W. Holley, Har Gobind Khorana and Marshall W. Nirenberg 'for their interpretation of the genetic code and its function in protein synthesis'."
- ^ a b c d e f g h i j k l m Watson JD, Baker TA, Bell SP, Gann A, Levine M, Oosick R. (2008). Molecular Biology of the Gene. San Francisco: Pearson/Benjamin Cummings. ISBN 0-8053-9592-X.
- ^ Nakamoto T (March 2009). "Evolution and the universality of the mechanism of initiation of protein synthesis". Gene 432 (1–2): 1–6. doi:10.1016/j.gene.2008.11.001. PMID 19056476.
- ^ a b Pamela K. Mulligan; King, Robert C.; Stansfield, William D. (2006). A dictionary of genetics. Oxford [Oxfordshire]: Oxford University Press. pp. 608. ISBN 0-19-530761-5.
- ^ Touriol C, Bornes S, Bonnal S, Audigier S, Prats H, Prats AC, Vagner S (2003). "Generation of protein isoform diversity by alternative initiation of translation at non-AUG codons". Biol. Cell 95 (3–4): 169–78. doi:10.1016/S0248-4900(03)00033-9. PMID 12867081.
- ^ Maloy S (2003-11-29). "How nonsense mutations got their names". Microbial Genetics Course. San Diego State University. http://www.sci.sdsu.edu/~smaloy/MicrobialGenetics/topics/rev-sup/amber-name.html. Retrieved 2010-03-10.
- ^ References for the image are found in Wikimedia Commons page at: Commons:File:Notable mutations.svg#References.
- ^ Griffiths, William M.; Miller, Jeffrey H.; Suzuki, David T. et al., eds (2000). "Spontaneous mutations". An Introduction to Genetic Analysis (7th ed.). New York: W. H. Freeman. ISBN 0-7167-3520-2. http://www.ncbi.nlm.nih.gov/books/bv.fcgi?rid=iga.section.2706.
- ^ Freisinger, E; Grollman, AP; Miller, H; Kisker, C (2004). "Lesion (in)tolerance reveals insights into DNA replication fidelity". The EMBO journal 23 (7): 1494–505. doi:10.1038/sj.emboj.7600158. PMC 391067. PMID 15057282. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=391067.
- ^ (Boillée 2006, p. 39)
- ^ Chang JC, Kan YW (June 1979). "beta 0 thalassemia, a nonsense mutation in man". Proc. Natl. Acad. Sci. U.S.A. 76 (6): 2886–9. doi:10.1073/pnas.76.6.2886. PMC 383714. PMID 88735. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=383714.
- ^ Boillée S, Vande Velde C, Cleveland DW (October 2006). "ALS: a disease of motor neurons and their nonneuronal neighbors". Neuron 52 (1): 39–59. doi:10.1016/j.neuron.2006.09.018. PMID 17015226.
- ^ Isbrandt D, Hopwood JJ, von Figura K, Peters C (1996). "Two novel frameshift mutations causing premature stop codons in a patient with the severe form of Maroteaux-Lamy syndrome". Hum. Mutat. 7 (4): 361–3. doi:10.1002/(SICI)1098-1004(1996)7:4<361::AID-HUMU12>3.0.CO;2-0. PMID 8723688.
- ^ Crow JF (1993). "How much do we know about spontaneous human mutation rates?". Environ. Mol. Mutagen. 21 (2): 122–9. doi:10.1002/em.2850210205. PMID 8444142.
- ^ Lewis, Ricki (2005). Human Genetics: Concepts and Applications (6th ed.). Boston, Mass: McGraw Hill. pp. 227–228. ISBN 0-07-111156-5.
- ^ Sawyer SA, Parsch J, Zhang Z, Hartl DL (2007). "Prevalence of positive selection among nearly neutral amino acid replacements in Drosophila". Proc. Natl. Acad. Sci. U.S.A. 104 (16): 6504–10. doi:10.1073/pnas.0701572104. PMC 1871816. PMID 17409186. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1871816.
- ^ Bridges KR (2002). "Malaria and the Red Cell". Harvard. http://sickle.bwh.harvard.edu/malaria_sickle.html.
- ^ Drake JW, Holland JJ (1999). "Mutation rates among RNA viruses". Proc. Natl. Acad. Sci. U.S.A. 96 (24): 13910–3. doi:10.1073/pnas.96.24.13910. PMC 24164. PMID 10570172. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=24164.
- ^ Holland J, Spindler K, Horodyski F, Grabau E, Nichol S, VandePol S (1982). "Rapid evolution of RNA genomes". Science 215 (4540): 1577–85. doi:10.1126/science.7041255. PMID 7041255.
- ^ Arjan J, de Visser DM, Rozen DE (2006). "Clonal Interference and the Periodic Selection of New Beneficial Mutations in Escherichia coli". Genetics, the Genetics Society of America 172 (4): 2093–2100. doi:10.1534/genetics.105.052373. PMC 1456385. PMID 16489229. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1456385.
- ^ Yang et al. (1990). Michel-Beyerle, M. E.. ed. Reaction centers of photosynthetic bacteria: Feldafing-II-Meeting. 6. Berlin: Springer-Verlag. pp. 209–18. ISBN 3-540-53420-2.
- ^ Füllen G, Youvan DC (1994). "Genetic Algorithms and Recursive Ensemble Mutagenesis in Protein Engineering". Complexity International 1. http://www.complexity.org.au/ci/vol01/fullen01/html/.
- ^ Hebbel RP (2003). "Sickle hemoglobin instability: a mechanism for malarial protection". Redox Rep. 8 (5): 238–40. doi:10.1179/135100003225002826. PMID 14962356.
- ^ Varani G, McClain WH (July 2000). "The G x U wobble base pair. A fundamental building block of RNA structure crucial to RNA function in diverse biological systems". EMBO Rep. 1 (1): 18–23. doi:10.1093/embo-reports/kvd001. PMC 1083677. PMID 11256617. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1083677.
- ^ Crick FHC, Orgel LE (1973). "Directed panspermia". Icarus 19 (3): 341–6. Bibcode 1973Icar...19..341C. doi:10.1016/0019-1035(73)90110-3. "It is a little surprising that organisms with somewhat different codes do not coexist." (p. 344) (Further discussion)
- ^ a b c Elzanowski A, Ostell J (2008-04-07). "The Genetic Codes". National Center for Biotechnology Information (NCBI). http://www.ncbi.nlm.nih.gov/Taxonomy/Utils/wprintgc.cgi?mode=c. Retrieved 2010-03-10.
- ^ Jukes TH, Osawa S (December 1990). "The genetic code in mitochondria and chloroplasts". Experientia 46 (11–12): 1117–26. doi:10.1007/BF01936921. PMID 2253709.
- ^ Santos, M.A.; Tuite, M.F. (1995). "The CUG codon is decoded in vivo as serine and not leucine in Candida albicans". Nucleic Acids Research 23 (9): 1481–6. doi:10.1093/nar/23.9.1481. PMC 306886. PMID 7784200. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=306886.
- ^ Butler, G. et al.; Rasmussen, MD; Lin, MF; Santos, MA; Sakthikumar, S; Munro, CA; Rheinbay, E; Grabherr, M et al. (2009). "Evolution of pathogenicity and sexual reproduction in eight Candida genomes". Nature 459 (7247): 657–62. doi:10.1038/nature08064. PMC 2834264. PMID 19465905. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2834264.
- ^ Xie J, Schultz PG (December 2005). "Adding amino acids to the genetic repertoire". Curr Opin Chem Biol 9 (6): 548–54. doi:10.1016/j.cbpa.2005.10.011. PMID 16260173.
- ^ Wang Q, Parrish AR, Wang L (March 2009). "Expanding the genetic code for biological studies". Chem. Biol. 16 (3): 323–36. doi:10.1016/j.chembiol.2009.03.001. PMC 2696486. PMID 19318213. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2696486.
- ^ Simon M (2005). Emergent computation: emphasizing bioinformatics. New York: AIP Press/Springer Science+Business Media. pp. 105–106. ISBN 0-387-22046-1.
- ^ a b Yarus M (2010). Life from an RNA World: The Ancestor Within. Cambridge: Harvard University Press. pp. 163. ISBN 0-674-05075-4.
- ^ Ribas de Pouplana L, Turner RJ, Steer BA, Schimmel P (September 1998). "Genetic code origins: tRNAs older than their synthetases?". Proc. Natl. Acad. Sci. U.S.A. 95 (19): 11295–300. doi:10.1073/pnas.95.19.11295. PMC 21636. PMID 9736730. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=21636.
- ^ Freeland SJ, Hurst LD (September 1998). "The genetic code is one in a million". J. Mol. Evol. 47 (3): 238–48. doi:10.1007/PL00006381. PMID 9732450.
- ^ Taylor FJ, Coates D (1989). "The code within the codons". BioSystems 22 (3): 177–87. doi:10.1016/0303-2647(89)90059-2. PMID 2650752.
- ^ Di Giulio M (October 1989). "The extension reached by the minimization of the polarity distances during the evolution of the genetic code". J. Mol. Evol. 29 (4): 288–93. doi:10.1007/BF02103616. PMID 2514270.
- ^ Wong JT (February 1980). "Role of minimization of chemical distances between amino acids in the evolution of the genetic code". Proc. Natl. Acad. Sci. U.S.A. 77 (2): 1083–6. doi:10.1073/pnas.77.2.1083. PMC 348428. PMID 6928661. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=348428.
- ^ Knight RD, Freeland SJ, Landweber LF (June 1999). "Selection, history and chemistry: the three faces of the genetic code". Trends Biochem. Sci. 24 (6): 241–7. doi:10.1016/S0968-0004(99)01392-4. PMID 10366854.
- ^ Knight RD, Landweber LF (September 1998). "Rhyme or reason: RNA-arginine interactions and the genetic code". Chem. Biol. 5 (9): R215–20. doi:10.1016/S1074-5521(98)90001-1. PMID 9751648.
- ^ Yarus M, Widmann JJ, Knight R (November 2009). "RNA-amino acid binding: a stereochemical era for the genetic code". J. Mol. Evol. 69 (5): 406–29. doi:10.1007/s00239-009-9270-1. PMID 19795157.
- ^ Brooks DJ, Fresco JR, Lesk AM, Singh M (October 2002). "Evolution of amino acid frequencies in proteins over deep time: inferred order of introduction of amino acids into the genetic code". Mol. Biol. Evol. 19 (10): 1645–55. PMID 12270892. http://mbe.oxfordjournals.org/content/19/10/1645.long.
- ^ Amirnovin R (May 1997). "An analysis of the metabolic theory of the origin of the genetic code". J. Mol. Evol. 44 (5): 473–6. doi:10.1007/PL00006170. PMID 9115171.
- ^ Ronneberg TA, Landweber LF, Freeland SJ (December 2000). "Testing a biosynthetic theory of the genetic code: fact or artifact?". Proc. Natl. Acad. Sci. U.S.A. 97 (25): 13690–5. doi:10.1073/pnas.250403097. PMC 17637. PMID 11087835. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=17637.
- ^ a b Freeland SJ, Wu T, Keulmann N (October 2003). "The case for an error minimizing standard genetic code". Orig Life Evol Biosph 33 (4–5): 457–77. doi:10.1023/A:1025771327614. PMID 14604186.
- ^ Baranov PV, Venin M, Provan G (2009). "Codon size reduction as the origin of the triplet genetic code". PLoS ONE 4 (5): e5708. doi:10.1371/journal.pone.0005708. PMC 2682656. PMID 19479032. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2682656.
- ^ Tlusty T (Nov 2007). "A model for the emergence of the genetic code as a transition in a noisy information channel". J. Theor. Bio. 249 (2): 331–42. doi:10.1016/j.jtbi.2007.07.029. PMID 17826800.
- ^ Sonneborn TM (1965). Bryson, V., Vogel, H.. ed. Evolving genes and proteins. New York: Academic Press. pp. 377–397.
- ^ Tlusty T (Feb 2008). "Rate-distortion scenario for the emergence and evolution of noisy molecular codes". Phys. Rev. Lett. 100 (4): 048101. Bibcode 2008PhRvL.100d8101T. doi:10.1103/PhysRevLett.100.048101. PMID 18352335.
- ^ Sella G, Ardell D (Jul 2006). "The coevolution of genes and genetic codes: Crick's frozen accident revisited". J. Mol. Evol. 63 (3): 297–313. doi:10.1007/s00239-004-0176-7. PMID 16838217.
- ^ Tlusty T (Sept 2010). "A colorful origin for the genetic code: Information theory, statistical mechanics and the emergence of molecular codes". Phys. Life. Rev. 7 (3): 362–376. doi:10.1016/j.plrev.2010.06.002. PMID 20558115.
Further reading
- Griffiths, Anthony J. F.; Miller, Jeffrey H.; Suzuki, David T.; Lewontin, Richard C.; Gelbart, William M. (1999). An Introduction to genetic analysis (7th ed.). San Francisco: W.H. Freeman. ISBN 0-7167-3771-X. http://www.ncbi.nlm.nih.gov/books/bv.fcgi?call=bv.View..ShowTOC&rid=iga.TOC.
- Alberts, Bruce; Johnson, Alexander; Lewis, Julian; Raff, Martin; Roberts, Keith; Walter, Peter (2002). Molecular biology of the cell (4th ed.). New York: Garland Science. ISBN 0-8153-3218-1. http://www.ncbi.nlm.nih.gov/books/bv.fcgi?call=bv.View..ShowTOC&rid=mboc4.TOC&depth=2.
- Lodish, Harvey F.; Berk, Arnold; Zipursky, S. Lawrence; Matsudaira, Paul; Baltimore, David; Darnell, James E. (2000). Molecular cell biology (4th ed.). San Francisco: W.H. Freeman. ISBN 0-7167-3706-X. http://www.ncbi.nlm.nih.gov/books/bv.fcgi?call=bv.View..ShowTOC&rid=mcb.TOC.
External links
- The Genetic Codes → Genetic Code Tables
- The Codon Usage Database → Codon frequency tables for many organisms
- History of deciphering the genetic code
- American Scientist: Ode to the code (Origin)
- Alphabet of Life (Origin)
- Symmetries in the genetic code
Gene expression Introduction to genetics General flow: DNA > RNA > Protein
Genetic codeTranscription (Transcription factors, RNA Polymerase,promoter) Prokaryotic / Archaeal / Eukaryotic
post-transcriptional modification (hnRNA,5' capping,Splicing,Polyadenylation)Translation (Ribosome,tRNA) Prokaryotic / Archaeal / Eukaryotic
post-translational modification (functional groups, peptides, structural changes)Gene regulation



{kind=link}
Wikimedia Foundation. 2010.