- Expected value
-
This article is about the term used in probability theory and statistics. For other uses, see Expected value (disambiguation).
In probability theory, the expected value (or expectation, or mathematical expectation, or mean, or the first moment) of a random variable is the weighted average of all possible values that this random variable can take on. The weights used in computing this average correspond to the probabilities in case of a discrete random variable, or densities in case of a continuous random variable. From a rigorous theoretical standpoint, the expected value is the integral of the random variable with respect to its probability measure.[1][2]
The expected value may be intuitively understood by the law of large numbers: The expected value, when it exists, is almost surely the limit of the sample mean as sample size grows to infinity. More informally, it can be interpreted as the long-run average of the results of many independent repetitions of an experiment (e.g. a dice roll). The value may not be expected in the ordinary sense—the "expected value" itself may be unlikely or even impossible (such as having 2.5 children), just like the sample mean.
The expected value does not exist for some distributions with large "tails", such as the Cauchy distribution.[3]
It is possible to construct an expected value equal to the probability of an event by taking the expectation of an indicator function that is one if the event has occurred and zero otherwise. This relationship can be used to translate properties of expected values into properties of probabilities, e.g. using the law of large numbers to justify estimating probabilities by frequencies.
Contents
Definition
Discrete random variable, finite case
Suppose random variable X can take value x1 with probability p1, value x2 with probability p2, and so on, up to value xk with probability pk. Then the expectation of this random variable X is defined as
Since all probabilities pi add up to one: p1 + p2 + ... + pk = 1, the expected value can be viewed as the weighted average, with pi’s being the weights:
If all outcomes xi are equally likely (that is, p1 = p2 = ... = pk), then the weighted average turns into the simple average. This is intuitive: the expected value of a random variable is the average of all values it can take; thus the expected value is what you expect to happen on average. If the outcomes xi are not equiprobable, then the simple average ought to be replaced with the weighted average, which takes into account the fact that some outcomes are more likely than the others. The intuition however remains the same: the expected value of X is what you expect to happen on average.
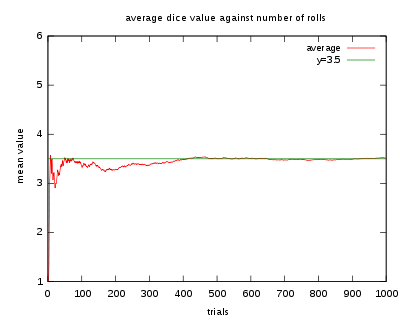 An illustration of the convergence of sequence averages of rolls of a die to the expected value of 3.5 as the number of rolls (trials) grows.
An illustration of the convergence of sequence averages of rolls of a die to the expected value of 3.5 as the number of rolls (trials) grows.
Example 1. Let X represent the outcome of a roll of a six-sided die. More specifically, X will be the number of pips showing on the top face of the die after the toss. The possible values for X are 1, 2, 3, 4, 5, 6, all equally likely (each having the probability of 1 6 ). The expectation of X is
If you roll the die n times and compute the average (mean) of the results, then as n grows, the average will almost surely converge to the expected value, a fact known as the strong law of large numbers. One example sequence of ten rolls of the die is 2, 3, 1, 2, 5, 6, 2, 2, 2, 6, which has the average of 3.1, with the distance of 0.4 from the expected value of 3.5. The convergence is relatively slow: the probability that the average falls within the range 3.5 ± 0.1 is 21.6% for ten rolls, 46.1% for a hundred rolls and 93.7% for a thousand rolls. See the figure for an illustration of the averages of longer sequences of rolls of the die and how they converge to the expected value of 3.5. More generally, the rate of convergence can be roughly quantified by e.g. Chebyshev's inequality and the Berry-Esseen theorem.
Example 2. The roulette game consists of a small ball and a wheel with 38 numbered pockets around the edge. As the wheel is spun, the ball bounces around randomly until it settles down in one of the pockets. Suppose random variable X represents the (monetary) outcome of a $1 bet on a single number ("straight up" bet). If the bet wins (which happens with probability 1 38 ), the payoff is $35; otherwise the player loses the bet. The expected profit from such a bet will be
Discrete random variable, countable case
Let X be a discrete random variable taking values x
1, x
2, ... with probabilities p
1, p
2, ... respectively. Then the expected value of this random variable is the infinite sumprovided that this series converges absolutely (that is, the sum must remain finite if we were to replace all x
i's with their absolute values). If this series does not converge absolutely, we say that the expected value of X does not exist.For example, suppose random variable X takes values 1, −2, 3, −4, ..., with respective probabilities c 12 , c 22 , c 32 , c 42 , ..., where c = 6 π2 is a normalizing constant that ensures the probabilities sum up to one. Then the infinite sum
converges and its sum is equal to ln(2) ≃ 0.69315. However it would be incorrect to claim that the expected value of X is equal to this number—in fact E[X] does not exist, as this series does not converge absolutely (see harmonic series).
Univariate continuous random variable
If the probability distribution of X admits a probability density function f(x), then the expected value can be computed as
General definition
In general, if X is a random variable defined on a probability space (Ω, Σ, P), then the expected value of X, denoted by E[X], ⟨X⟩, X or E[X], is defined as Lebesgue integral
When this integral exists, it is defined as the expectation of X. Note that not all random variables have a finite expected value, since the integral may not converge absolutely; furthermore, for some it is not defined at all (e.g., Cauchy distribution). Two variables with the same probability distribution will have the same expected value, if it is defined.
It follows directly from the discrete case definition that if X is a constant random variable, i.e. X = b for some fixed real number b, then the expected value of X is also b.
The expected value of an arbitrary function of X, g(X), with respect to the probability density function ƒ(x) is given by the inner product of ƒ and g:
This is sometimes called the law of the unconscious statistician. Using representations as Riemann–Stieltjes integral and integration by parts the formula can be restated as
 if
if  ,
, if
if  .
.
As a special case let α denote a positive real number, then
In particular, for α = 1, this reduces to:
if Pr[X ≥ 0] = 1, where F is the cumulative distribution function of X.
Conventional terminology
- When one speaks of the "expected price", "expected height", etc. one means the expected value of a random variable that is a price, a height, etc.
- When one speaks of the "expected number of attempts needed to get one successful attempt", one might conservatively approximate it as the reciprocal of the probability of success for such an attempt. Cf. expected value of the geometric distribution.
Properties
Constants
The expected value of a constant is equal to the constant itself; i.e., if c is a constant, then E[c] = c.
Monotonicity
If X and Y are random variables such that X ≤ Y almost surely, then E[X] ≤ E[Y].
Linearity
The expected value operator (or expectation operator) E is linear in the sense that
Note that the second result is valid even if X is not statistically independent of Y. Combining the results from previous three equations, we can see that
for any two random variables X and Y (which need to be defined on the same probability space) and any real numbers a and b.
Iterated expectation
Iterated expectation for discrete random variables
For any two discrete random variables X, Y one may define the conditional expectation:[4]
which means that E[X|Y](y) is a function of y.
Then the expectation of X satisfies
Hence, the following equation holds:[5]
that is,
The right hand side of this equation is referred to as the iterated expectation and is also sometimes called the tower rule or the tower property. This proposition is treated in law of total expectation.
Iterated expectation for continuous random variables
In the continuous case, the results are completely analogous. The definition of conditional expectation would use inequalities, density functions, and integrals to replace equalities, mass functions, and summations, respectively. However, the main result still holds:
Inequality
If a random variable X is always less than or equal to another random variable Y, the expectation of X is less than or equal to that of Y:
If X ≤ Y, then E[X] ≤ E[Y].
In particular, if we set Y to |X| we know X ≤ Y and −X ≤ Y. Therefore we know E[X] ≤ E[Y] and E[-X] ≤ E[Y]. From the linearity of expectation we know -E[X] ≤ E[Y].
Therefore the absolute value of expectation of a random variable is less than or equal to the expectation of its absolute value:
Non-multiplicativity
If one considers the joint probability density function of X and Y, say j(x,y), then the expectation of XY is
In general, the expected value operator is not multiplicative, i.e. E[XY] is not necessarily equal to E[X]·E[Y]. In fact, the amount by which multiplicativity fails is called the covariance:
Thus multiplicativity holds precisely when Cov(X, Y) = 0, in which case X and Y are said to be uncorrelated (independent variables are a notable case of uncorrelated variables).
Now if X and Y are independent, then by definition j(x,y) = ƒ(x)g(y) where ƒ and g are the marginal PDFs for X and Y. Then
and Cov(X, Y) = 0.
Observe that independence of X and Y is required only to write j(x,y) = ƒ(x)g(y), and this is required to establish the second equality above. The third equality follows from a basic application of the Fubini-Tonelli theorem.
Functional non-invariance
In general, the expectation operator and functions of random variables do not commute; that is
A notable inequality concerning this topic is Jensen's inequality, involving expected values of convex (or concave) functions.
Uses and applications
The expected values of the powers of X are called the moments of X; the moments about the mean of X are expected values of powers of X − E[X]. The moments of some random variables can be used to specify their distributions, via their moment generating functions.
To empirically estimate the expected value of a random variable, one repeatedly measures observations of the variable and computes the arithmetic mean of the results. If the expected value exists, this procedure estimates the true expected value in an unbiased manner and has the property of minimizing the sum of the squares of the residuals (the sum of the squared differences between the observations and the estimate). The law of large numbers demonstrates (under fairly mild conditions) that, as the size of the sample gets larger, the variance of this estimate gets smaller.
This property is often exploited in a wide variety of applications, including general problems of statistical estimation and machine learning, to estimate (probabilistic) quantities of interest via Monte Carlo methods, since most quantities of interest can be written in terms of expectation, e.g.
 where
where  is the indicator function for set
is the indicator function for set  , i.e.
, i.e.  .
.In classical mechanics, the center of mass is an analogous concept to expectation. For example, suppose X is a discrete random variable with values xi and corresponding probabilities pi. Now consider a weightless rod on which are placed weights, at locations xi along the rod and having masses pi (whose sum is one). The point at which the rod balances is E[X].
Expected values can also be used to compute the variance, by means of the computational formula for the variance
A very important application of the expectation value is in the field of quantum mechanics. The expectation value of a quantum mechanical operator
 operating on a quantum state vector
operating on a quantum state vector  is written as
is written as  . The uncertainty in can be calculated using the formula
. The uncertainty in can be calculated using the formula  .
.Expectation of matrices
If X is an
 matrix, then the expected value of the matrix is defined as the matrix of expected values:
matrix, then the expected value of the matrix is defined as the matrix of expected values:This is utilized in covariance matrices.
Formulas for special cases
Discrete distribution taking only non-negative integer values
When a random variable takes only values in {0,1,2,3,...} we can use the following formula for computing its expectation (even when the expectation is infinite):
Proof:
interchanging the order of summation, we have
as claimed. This result can be a useful computational shortcut. For example, suppose we toss a coin where the probability of heads is p. How many tosses can we expect until the first heads (not including the heads itself)? Let X be this number. Note that we are counting only the tails and not the heads which ends the experiment; in particular, we can have X = 0. The expectation of X may be computed by
 . This is because the number of tosses is at least i exactly when the first i tosses yielded tails. This matches the expectation of a random variable with an Exponential distribution. We used the formula for Geometric progression:
. This is because the number of tosses is at least i exactly when the first i tosses yielded tails. This matches the expectation of a random variable with an Exponential distribution. We used the formula for Geometric progression: 
Continuous distribution taking non-negative values
Analogously with the discrete case above, when a continuous random variable X takes only non-negative values, we can use the following formula for computing its expectation (even when the expectation is infinite):
Proof: It is first assumed that X has a density fX(x). We present two techniques:
- Using integration by parts (a special case of Section 1.4 above):
and the bracket vanishes because[6] 1 − F(x) = o(1 / x) as
 .
.- Using an interchange in order of integration:
In case no density exists, it is seen that
History
The idea of the expected value originated in the middle of the 17th century from the study of the so-called problem of points. This problem is: how to divide the stakes in a fair way between two players who have to end their game before it's properly finished? This problem had been debated for centuries, and many conflicting proposals and solutions had been suggested over the years, when it was posed in 1654 to Blaise Pascal by a French nobleman chevalier de Méré. de Méré claimed that this problem couldn't be solved and that it showed just how flawed mathematics was when it came to its application to the real world. Pascal, being a mathematician, got provoked and determined to solve the problem once and for all. He began to discuss the problem in a now famous series of letters to Pierre de Fermat. Soon enough they both independently came up with a solution. They solved the problem in different computational ways but their results were identical because their computations were based on the same fundamental principle. The principle is that the value of a future gain should be directly proportional to the chance of getting it. This principle seemed to have come absolutely natural to both of them. They were very pleased by the fact that they had found essentially the same solution and this in turn made them absolutely convinced they had solved the problem conclusively. However, they did not publish their findings. They only informed a small circle of mutual scientific friends in Paris about it.[7]
Three years later, in 1657, a Dutch mathematician Christiaan Huygens, who had just visited Paris, published a treatise (see Huygens (1657)) "De ratiociniis in ludo aleæ" on probability theory. In this book he considered the problem of points and presented a solution based on the same principle as the solutions of Pascal and Fermat. Huygens also extended the concept of expectation by adding rules for how to calculate expectations in more complicated situations than the original problem (e.g., for three or more players). In this sense this book can be seen as the first successful attempt of laying down the foundations of the theory of probability.
In the foreword to his book, Huygens wrote: "It should be said, also, that for some time some of the best mathematicians of France have occupied themselves with this kind of calculus so that no one should attribute to me the honour of the first invention. This does not belong to me. But these savants, although they put each other to the test by proposing to each other many questions difficult to solve, have hidden their methods. I have had therefore to examine and go deeply for myself into this matter by beginning with the elements, and it is impossible for me for this reason to affirm that I have even started from the same principle. But finally I have found that my answers in many cases do not differ from theirs." (cited by Edwards (2002)). Thus, Huygens learned about de Méré's problem in 1655 during his visit to France; later on in 1656 from his correspondence with Carcavi he learned that his method was essentially the same as Pascal's; so that before his book went to press in 1657 he knew about Pascal's priority in this subject.
Neither Pascal nor Huygens used the term "expectation" in its modern sense. In particular, Huygens writes: "That my Chance or Expectation to win any thing is worth just such a Sum, as wou'd procure me in the same Chance and Expectation at a fair Lay. ... If I expect a or b, and have an equal Chance of gaining them, my Expectation is worth a+b 2 ." More than a hundred years later, in 1814, Pierre-Simon Laplace published his tract "Théorie analytique des probabilités", where the concept of expected value was defined explicitly:... this advantage in the theory of chance is the product of the sum hoped for by the probability of obtaining it; it is the partial sum which ought to result when we do not wish to run the risks of the event in supposing that the division is made proportional to the probabilities. This division is the only equitable one when all strange circumstances are eliminated; because an equal degree of probability gives an equal right for the sum hoped for. We will call this advantage mathematical hope.The use of letter E to denote expected value goes back to W.A. Whitworth (1901) "Choice and chance". The symbol has become popular since for English writers it meant "Expectation", for Germans "Erwartungswert", and for French "Espérance mathématique".[8]
See also
- Conditional expectation
- An inequality on location and scale parameters
- Expected value is also a key concept in economics, finance, and many other subjects
- The general term expectation
- Moment (mathematics)
- Expectation value (quantum mechanics)
- Wald's equation for calculating the expected value of a random number of random variables
Notes
- ^ Sheldon M Ross (2007). "§2.4 Expectation of a random variable". Introduction to probability models (9th ed.). Academic Press. p. 38 ff. ISBN 0125980620. http://books.google.com/books?id=12Pk5zZFirEC&pg=PA38.
- ^ Richard W Hamming (1991). "§2.5 Random variables, mean and the expected value". The art of probability for scientists and engineers. Addison-Wesley. p. 64 ff. ISBN 0201406861. http://books.google.com/books?id=jX_F-77TA3gC&pg=PA64.
- ^ For a discussion of the Cauchy distribution, see Richard W Hamming (1991). "Example 8.7–1 The Cauchy distribution". The art of probability for scientists and engineers. Addison-Wesley. p. 290 ff. ISBN 0201406861. http://books.google.com/books?id=jX_F-77TA3gC&printsec=frontcover&dq=isbn:0201406861&cd=1#v=onepage&q=Cauchy&f=false. "Sampling from the Cauchy distribution and averaging gets you nowhere — one sample has the same distribution as the average of 1000 samples!"
- ^ Sheldon M Ross. "Chapter 3: Conditional probability and conditional expectation". cited work. p. 97 ff. ISBN 0125980620. http://books.google.com/books?id=12Pk5zZFirEC&pg=PA97.
- ^ Sheldon M Ross. "§3.4: Computing expectations by conditioning". cited work. p. 105 ff. ISBN 0125980620. http://books.google.com/books?id=12Pk5zZFirEC&pg=PA105.
- ^ http://en.wikipedia.org/wiki/Cumulative_distribution_function#Properties_2
- ^ "Ore, Pascal and the Invention of Probability Theory", The American Mathematical Monthly, Vol 67, No 5 (May, 1960), pp 409-419
- ^ "Earliest uses of symbols in probability and statistics". http://jeff560.tripod.com/stat.html.
Literature
Theory of probability distributions probability mass function (pmf) · probability density function (pdf) · cumulative distribution function (cdf) · quantile function Categories:
Categories:- Theory of probability distributions
- Gambling terminology
![\operatorname{E}[X] = x_1p_1 + x_2p_2 + \ldots + x_kp_k \;.](0/8109a4769d528a0d042f00fcc2727cbc.png)
![\operatorname{E}[X] = \frac{x_1p_1 + x_2p_2 + \ldots + x_kp_k}{p_1 + p_2 + \ldots + p_k} \;.](d/dfd8075c47f52dc66e5e4efe3cf086ee.png)

![\operatorname{E}[X] = 1\cdot\frac16 + 2\cdot\frac16 + 3\cdot\frac16 + 4\cdot\frac16 + 5\cdot\frac16 + 6\cdot\frac16 = 3.5.](9/129afdb4f91b4f2da70537e8a4fd52bc.png)
![\operatorname{E}[\,\text{gain from }$1\text{ bet}\,] =
-$1 \cdot \frac{37}{38}\ +\ $35 \cdot \frac{1}{38} = -$0.0526.](d/43d7addf31a87e8ee10a864aeb630ef6.png)
![\operatorname{E}[X] = \sum_{i=1}^\infty x_i\, p_i,](4/414e2f3ba53c8f5c93aa53bc1db6fd98.png)

![\operatorname{E}[X] = \int_{-\infty}^\infty x f(x)\, \operatorname{d}x .](5/fb585591af7f5d9e28d27779acaf854c.png)
![\operatorname{E}[X] = \int_\Omega X\, \operatorname{d}P = \int_\Omega X(\omega)\, P(\operatorname{d}\omega)](5/1d576e68f8c71cdf7c8451e7b3109939.png)









![\operatorname{E}_Y\left[ \operatorname{E}_{X|Y=y}(x) \right]=](c/89c910a41f9fd8b7ef0bb2ac03bc4e4c.png)









![\operatorname{E}_X(x) = \operatorname{E}_Y\left[ \operatorname{E}_{X|Y=y}(x) \right].](f/ecf633d781b5c7f27d67953158dedc03.png)



![\begin{align}
\operatorname{E}(XY) & = \int \int xy \,j(x,y)\,dx\,dy=
\int\int x y f(x) g(y)\,dy\,dx \\
& = \left[\int x f(x)\,dx\right]\left[\int y g(y)\,dy\right]=\operatorname{E}(X)\operatorname{E}(Y)
\end{align}](7/5978e8566fbc245b975fc9bc95801917.png)







![\operatorname{E}(X) = \int_0^\infty (-x)(-f_X(x))\;dx = \left[ -x(1 - F(x)) \right]_0^\infty + \int_0^\infty (1 - F(x))\;dx](6/09658a8a06def060c62d58e58bfe1975.png)



Wikimedia Foundation. 2010.