- Eigenvalues and eigenvectors
-
For more specific information regarding the eigenvalues and eigenvectors of matrices, see Eigendecomposition of a matrix.
 In this shear mapping the red arrow changes direction but the blue arrow does not. Therefore the blue arrow is an eigenvector, with eigenvalue 1 as its length is unchanged.
In this shear mapping the red arrow changes direction but the blue arrow does not. Therefore the blue arrow is an eigenvector, with eigenvalue 1 as its length is unchanged.
The eigenvectors of a square matrix are the non-zero vectors that, after being multiplied by the matrix, remain parallel to the original vector. For each eigenvector, the corresponding eigenvalue is the factor by which the eigenvector is scaled when multiplied by the matrix. The prefix eigen- is adopted from the German word "eigen" for "own"[1] in the sense of a characteristic description. The eigenvectors are sometimes also called characteristic vectors. Similarly, the eigenvalues are also known as characteristic values.
The mathematical expression of this idea is as follows: if A is a square matrix, a non-zero vector v is an eigenvector of A if there is a scalar λ (lambda) such that
The scalar λ (lambda) is said to be the eigenvalue of A corresponding to v. An eigenspace of A is the set of all eigenvectors with the same eigenvalue together with the zero vector. However, the zero vector is not an eigenvector.[2]
These ideas often are extended to more general situations, where scalars are elements of any field, vectors are elements of any vector space, and linear transformations may or may not be represented by matrix multiplication. For example, instead of real numbers, scalars may be complex numbers; instead of arrows, vectors may be functions or frequencies; instead of matrix multiplication, linear transformations may be operators such as the derivative from calculus. These are only a few of countless examples where eigenvectors and eigenvalues are important.
In such cases, the concept of direction loses its ordinary meaning, and is given an abstract definition. Even so, if that abstract direction is unchanged by a given linear transformation, the prefix "eigen" is used, as in eigenfunction, eigenmode, eigenface, eigenstate, and eigenfrequency.
Eigenvalues and eigenvectors have many applications in both pure and applied mathematics. They are used in matrix factorization, in quantum mechanics, and in many other areas.
Contents
Definition
Prerequisites and motivation
 Matrix A acts by stretching the vector x, not changing its direction, so x is an eigenvector of A.
Matrix A acts by stretching the vector x, not changing its direction, so x is an eigenvector of A.Eigenvectors and eigenvalues depend on the concepts of vectors and linear transformations. In the most elementary case, vectors can be thought of as arrows that have both length (or magnitude) and direction. Once a set of Cartesian coordinates is established, a vector can be described relative to that set of coordinates by a sequence of numbers. A linear transformation can be described by a square matrix. For example, in the standard coordinates of n-dimensional space, a vector can be written
A matrix can be written
Here n is some fixed natural number.
Usually, the multiplication of a vector x by a square matrix A changes both the magnitude and the direction of the vector it acts on—but in the special case where it changes only the scale (magnitude) of the vector and leaves the direction unchanged, or switches the vector to the opposite direction, that vector is called an eigenvector of that matrix. (The term "eigenvector" is meaningless except in relation to some particular matrix.) When multiplied by a matrix, each eigenvector of that matrix changes its magnitude by a factor, called the eigenvalue corresponding to that eigenvector.
The vector x is an eigenvector of the matrix A with eigenvalue λ (lambda) if the following equation holds:
This equation can be interpreted geometrically as follows: a vector x is an eigenvector if multiplication by A stretches, shrinks, leaves unchanged, flips (points in the opposite direction), flips and stretches, or flips and shrinks x. If the eigenvalue λ > 1, x is stretched by this factor. If λ = 1, the vector x is not affected at all by multiplication by A. If 0 < λ < 1, x is shrunk (or compressed). The case λ = 0 means that x shrinks to a point (represented by the origin), meaning that x is in the kernel of the linear map given by A. If λ < 0 then x flips and points in the opposite direction as well as being scaled by a factor equal to the absolute value of λ.
As a special case, the identity matrix I is the matrix that leaves all vectors unchanged:
Every non-zero vector x is an eigenvector of the identity matrix with eigenvalue 1.
Example
For the matrix A
the vector
is an eigenvector with eigenvalue 1. Indeed,
On the other hand the vector
is not an eigenvector, since
and this vector is not a multiple of the original vector x.
Formal definition
In abstract mathematics, a more general definition is given:
Let V be any vector space, let x be a vector in that vector space, and let T be a linear transformation mapping V into V. Then x is an eigenvector of T with eigenvalue λ if the following equation holds:
This equation is called the eigenvalue equation. Note that Tx means T of x, the action of the transformation T on x, while λx means the product of the number λ times the vector x.[3] Most, but not all [4] authors also require x to be non-zero. The set of eigenvalues of T is sometimes called the spectrum of T.
Eigenvalues and eigenvectors of matrices
Characteristic polynomial
Main article: Characteristic polynomialThe eigenvalues of A are precisely the solutions λ to the equation
Here det is the determinant of matrix formed by A - λI and I is the n×n identity matrix. This equation is called the characteristic equation (or, less often, the secular equation) of A. For example, if A is the following matrix (a so-called diagonal matrix):
then the characteristic equation reads

-
-
-
-
 .
.
-
-
-
-
The solutions to this equation are the eigenvalues λi = ai,i (i = 1, ..., n).
Proving the afore-mentioned relation of eigenvalues and solutions of the characteristic equation requires some linear algebra, specifically the notion of linearly independent vectors: briefly, the eigenvalue equation for a matrix A can be expressed as
which can be rearranged to
If there exists an inverse
then both sides can be left-multiplied by it, to obtain x = 0. Therefore, if λ is such that A − λI is invertible, λ cannot be an eigenvalue. It can be shown that the converse holds, too: if A − λI is not invertible, λ is an eigenvalue. A criterion from linear algebra states that a matrix (here: A − λI) is non-invertible if and only if its determinant is zero, thus leading to the characteristic equation.
The left-hand side of this equation can be seen (using Leibniz' rule for the determinant) to be a polynomial function in λ, whose coefficients depend on the entries of A. This polynomial is called the characteristic polynomial. Its degree is n, that is to say, the highest power of λ occurring in this polynomial is λn. At least for small matrices, the solutions of the characteristic equation (hence, the eigenvalues of A) can be found directly. Moreover, it is important for theoretical purposes, such as the Cayley–Hamilton theorem. It also shows that any n×n matrix has at most n eigenvalues. However, the characteristic equation need not have n distinct solutions. In other words, there may be strictly less than n distinct eigenvalues. This happens for the matrix describing the shear mapping discussed below.
If the matrix has real entries, the coefficients of the characteristic polynomial are all real. However, the roots are not necessarily real; they may include complex numbers with a non-zero imaginary component. For example, a 2×2 matrix describing a 45° rotation will not leave any non-zero vector pointing in the same direction. However, there is at least one complex number λ solving the characteristic equation, even if the entries of the matrix A are complex numbers to begin with. (This existence of such a solution is known as the fundamental theorem of algebra.) For a complex eigenvalue, the corresponding eigenvectors also have complex components.
Eigenspace
If x is an eigenvector of the matrix A with eigenvalue λ, then any scalar multiple αx is also an eigenvector of A with the same eigenvalue, since A(αx) = αAx = αλx = λ(αx). More generally, any non-zero linear combination of eigenvectors that share the same eigenvalue λ, will itself be an eigenvector with eigenvalue λ.[5] Together with the zero vector, the eigenvectors of A with the same eigenvalue form a linear subspace of the vector space called an eigenspace, Eλ. In case of dim(Eλ) = 1, it is called an eigenline and λ is called a scaling factor.
Diagonalizable matrices can be decomposed into a direct sum of eigenspaces, as per the eigendecomposition of a matrix. If a matrix is not diagonalizable, then it is called defective, and, while it cannot be decomposed into eigenspaces, it can be decomposed into the more general concept of generalized eigenspaces, as discussed here.
Algebraic and geometric multiplicities
Given an n×n matrix A and an eigenvalue λi of this matrix, there are two numbers measuring, roughly speaking, the number of eigenvectors belonging to λi. They are called multiplicities: the algebraic multiplicity of an eigenvalue is defined as the multiplicity of the corresponding root of the characteristic polynomial. The geometric multiplicity of an eigenvalue is defined as the dimension of the associated eigenspace, i.e. number of linearly independent eigenvectors with that eigenvalue. Both algebraic and geometric multiplicity are integers between (including) 1 and n. The algebraic multiplicity ni and geometric multiplicity mi may or may not be equal, but we always have mi ≤ ni. The simplest case is of course when mi = ni = 1. The total number of linearly independent eigenvectors, Nx, is given by summing the geometric multiplicities
Over a complex vector space, the sum of the algebraic multiplicities will equal the dimension of the vector space, but the sum of the geometric multiplicities may be smaller. In this case, it is possible that there may not be sufficient eigenvectors to span the entire space – more formally, there is no basis of eigenvectors (an eigenbasis). A matrix is diagonalizable by a suitable choice of coordinates if and only if there is an eigenbasis; if a matrix is not diagonalizable, it is said to be defective. For defective matrices, the notion of eigenvector can be generalized to generalized eigenvectors, and over an algebraically closed field a basis of generalized eigenvectors always exists, as follows from Jordan form.
The eigenvectors corresponding to different eigenvalues are linearly independent, meaning, in particular, that in an n-dimensional space the linear transformation A cannot have more than n eigenvalues (or eigenspaces).[6] All defective matrices have fewer than n distinct eigenvalues, but not all matrices with fewer than n distinct eigenvalues are defective[7] – for example, the identity matrix is diagonalizable (and indeed diagonal in any basis), but only has the eigenvalue 1.
Given an ordered choice of linearly independent eigenvectors, especially an eigenbasis, they can be indexed by eigenvalues, i.e. using a double index, with xi,j being the j th eigenvector for the i th eigenvalue. The eigenvectors can also be indexed using the simpler notation of a single index xk, with k = 1, 2, ... , Nx.
Worked example
These concepts are explained for the matrix
The characteristic equation of this matrix reads
Calculating the determinant, this yields the quadratic equation
whose solutions (also called roots) are λ = 1 and λ = 3. The eigenvectors for the eigenvalue λ = 3 are determined by using the eigenvalue equation, which in this case reads
The juxtaposition at the left hand side denotes matrix multiplication. Spelling this out, this equation comparing two vectors is tantamount to a system of the following two linear equations:
Both equations reduce to the single linear equation x = y. That is to say, any vector of the form (x, y) with y = x is an eigenvector to the eigenvalue λ = 3. However, the vector (0, 0) is excluded. A similar calculation shows that the eigenvectors corresponding to the eigenvalue λ = 1, are given by non-zero vectors (x, y) such that y = −x. For example, an eigenvector corresponding to λ = 1, is
 whereas an eigenvector corresponding to λ = 3, is
whereas an eigenvector corresponding to λ = 3, is  . These vectors, placed as columns in a matrix, may be used to create a diagonalizable matrix.
. These vectors, placed as columns in a matrix, may be used to create a diagonalizable matrix.Eigendecomposition
Main article: Eigendecomposition of a matrixThe spectral theorem for matrices can be stated as follows. Let A be a square n × n matrix. Let q1 ... qk be an eigenvector basis, i.e. an indexed set of k linearly independent eigenvectors, where k is the dimension of the space spanned by the eigenvectors of A. If k = n, then A can be written
where Q is the square n × n matrix whose i-th column is the basis eigenvector qi of A and Λ is the diagonal matrix whose diagonal elements are the corresponding eigenvalues, i.e. Λii = λi.
Further properties
Let A be an n×n matrix with eigenvalues λi,
 . Then
. Then- Trace of A
 .
.
- Determinant of A
 .
.
- Eigenvalues of Ak are

- These first three results follow by putting the matrix in upper-triangular form, in which case the eigenvalues are on the diagonal and the trace and determinant are respectively the sum and product of the diagonal.
- If A = AH, i.e., A is Hermitian, every eigenvalue is real.
- Every eigenvalue of a Unitary matrix has absolute value | λ | = 1.
Examples in the plane
The following table presents some example transformations in the plane along with their 2×2 matrices, eigenvalues, and eigenvectors.
horizontal shear scaling unequal scaling counterclockwise rotation by φ illustration 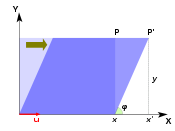
matrix 



characteristic equation λ2 − 2λ+1 = (1 − λ)2 = 0 λ2 − 2λk + k2 = (λ − k)2 = 0 (λ − k1)(λ − k2) = 0 λ2 − 2λ cos φ + 1 = 0 eigenvalues λi λ1=1 λ1=k λ1 = k1, λ2 = k2 λ1,2 = cos φ ± i sin φ = e ± iφ algebraic and geometric multiplicities n1 = 2, m1 = 1 n1 = 2, m1 = 2 n1 = m1 = 1, n2 = m2 = 1 n1 = m1 = 1, n2 = m2 = 1 eigenvectors 


Shear
Shear in the plane is a transformation where all points along a given line remain fixed while other points are shifted parallel to that line by a distance proportional to their perpendicular distance from the line.[8] In the horizontal shear depicted above, a point P of the plane moves parallel to the x-axis to the place P' so that its coordinate y does not change while the x coordinate increments to become x' = x + k y, where k is called the shear factor. The shear angle φ is determined by k = cot φ.
Repeatedly applying the shear transformation changes the direction of any vector in the plane closer and closer to the direction of the eigenvector.
Uniform scaling and reflection
Multiplying every vector with a constant real number k is represented by the diagonal matrix whose entries on the diagonal are all equal to k. Mechanically, this corresponds to stretching a rubber sheet equally in all directions such as a small area of the surface of an inflating balloon. All vectors originating at origin (i.e., the fixed point on the balloon surface) are stretched equally with the same scaling factor k while preserving its original direction. Thus, every non-zero vector is an eigenvector with eigenvalue k. Whether the transformation is stretching (elongation, extension, inflation), or shrinking (compression, deflation) depends on the scaling factor: if k > 1, it is stretching; if 0 < k < 1, it is shrinking. Negative values of k correspond to a reversal of direction, followed by a stretch or a shrink, depending on the absolute value of k.
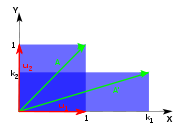
Unequal scaling
For a slightly more complicated example, consider a sheet that is stretched unequally in two perpendicular directions along the coordinate axes, or, similarly, stretched in one direction, and shrunk in the other direction. In this case, there are two different scaling factors: k1 for the scaling in direction x, and k2 for the scaling in direction y. If a given eigenvalue is greater than 1, the vectors are stretched in the direction of the corresponding eigenvector; if less than 1, they are shrunken in that direction. Negative eigenvalues correspond to reflections followed by a stretch or shrink. In general, matrices that are diagonalizable over the real numbers represent scalings and reflections: the eigenvalues represent the scaling factors (and appear as the diagonal terms), and the eigenvectors are the directions of the scalings.
The figure shows the case where k1 > 1 and 1 > k2 > 0. The rubber sheet is stretched along the x axis and simultaneously shrunk along the y axis. After repeatedly applying this transformation of stretching/shrinking many times, almost any vector on the surface of the rubber sheet will be oriented closer and closer to the direction of the x axis (the direction of stretching). The exceptions are vectors along the y-axis, which will gradually shrink away to nothing.
Rotation
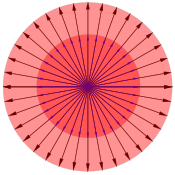
For more details on this topic, see Rotation matrix.A rotation in a plane is a transformation that describes motion of a vector, plane, coordinates, etc., around a fixed point. Clearly, for rotations other than through 0° and 180°, every vector in the real plane will have its direction changed, and thus there cannot be any eigenvectors. But this is not necessarily true if we consider the same matrix over a complex vector space. The characteristic equation is a quadratic equation with discriminant D = 4 (cos2 φ − 1) = − 4 sin2 φ, which is a negative number whenever φ is not equal to a multiple of 180°. A rotation of 0°, 360°, … is just the identity transformation (a uniform scaling by +1), while a rotation of 180°, 540°, …, is a reflection (uniform scaling by -1). Otherwise, as expected, there are no real eigenvalues or eigenvectors for rotation in the plane. Instead, the eigenvalues are complex numbers in general. Although not diagonalizable over the reals, the rotation matrix is diagonalizable over the complex numbers, and again the eigenvalues appear on the diagonal. Thus rotation matrices acting on complex spaces can be thought of as scaling matrices, with complex scaling factors.
Calculation
The complexity of the problem for finding roots/eigenvalues of the characteristic polynomial increases rapidly with increasing the degree of the polynomial (the dimension of the vector space). There are exact solutions for dimensions below 5, but for dimensions greater than or equal to 5 there are generally no exact solutions and one has to resort to numerical methods to find them approximately. (In fact, since the roots of any polynomial can be expressed as eigenvalues of a companion matrix, the Abel–Ruffini theorem implies that there is no general algebraic solution for eigenvalues of 5×5 or larger matrices: any general eigenvalue algorithm is necessarily approximate, although in practice one can obtain any desired accuracy.[9]) Worse, any computational procedure that starts by computing the coefficients of the characteristic polynomial can be very inaccurate in the presence of round-off error, because the roots of a polynomial are an extremely sensitive function of the coefficients (see Wilkinson's polynomial).[9] Efficient, accurate methods to compute eigenvalues and eigenvectors of arbitrary matrices were not known until the advent of the QR algorithm in 1961. [9] Besides, combining Householder transformation with LU decomposition can get better convergence than QR algorithm.[10] For large Hermitian sparse matrices, the Lanczos algorithm is one example of an efficient iterative method to compute eigenvalues and eigenvectors, among several other possibilities.[9]
History
Eigenvalues are often introduced in the context of linear algebra or matrix theory. Historically, however, they arose in the study of quadratic forms and differential equations.
Euler studied the rotational motion of a rigid body and discovered the importance of the principal axes. Lagrange realized that the principal axes are the eigenvectors of the inertia matrix.[11] In the early 19th century, Cauchy saw how their work could be used to classify the quadric surfaces, and generalized it to arbitrary dimensions.[12] Cauchy also coined the term racine caractéristique (characteristic root) for what is now called eigenvalue; his term survives in characteristic equation.[13]
Fourier used the work of Laplace and Lagrange to solve the heat equation by separation of variables in his famous 1822 book Théorie analytique de la chaleur.[14] Sturm developed Fourier's ideas further and brought them to the attention of Cauchy, who combined them with his own ideas and arrived at the fact that real symmetric matrices have real eigenvalues.[12] This was extended by Hermite in 1855 to what are now called Hermitian matrices.[13] Around the same time, Brioschi proved that the eigenvalues of orthogonal matrices lie on the unit circle,[12] and Clebsch found the corresponding result for skew-symmetric matrices.[13] Finally, Weierstrass clarified an important aspect in the stability theory started by Laplace by realizing that defective matrices can cause instability.[12]
In the meantime, Liouville studied eigenvalue problems similar to those of Sturm; the discipline that grew out of their work is now called Sturm–Liouville theory.[15] Schwarz studied the first eigenvalue of Laplace's equation on general domains towards the end of the 19th century, while Poincaré studied Poisson's equation a few years later.[16]
At the start of the 20th century, Hilbert studied the eigenvalues of integral operators by viewing the operators as infinite matrices.[17] He was the first to use the German word eigen to denote eigenvalues and eigenvectors in 1904, though he may have been following a related usage by Helmholtz. For some time, the standard term in English was "proper value", but the more distinctive term "eigenvalue" is standard today.[18]
The first numerical algorithm for computing eigenvalues and eigenvectors appeared in 1929, when Von Mises published the power method. One of the most popular methods today, the QR algorithm, was proposed independently by John G.F. Francis[19] and Vera Kublanovskaya[20] in 1961.[21]
Generalizations
Left and right eigenvectors
The word eigenvector formally refers to the right eigenvector xR. It is defined by the above eigenvalue equation
and is the most commonly used eigenvector. However, the left eigenvector xL exists as well, and is defined by
Infinite-dimensional spaces and spectral theory
For more details on this topic, see Spectral theorem.If the vector space is an infinite dimensional Banach space, the notion of eigenvalues can be generalized to the concept of spectrum. The spectrum is the set of scalars λ for which (T − λI)−1 is not defined; that is, such that T − λI has no bounded inverse.
Clearly if λ is an eigenvalue of T, λ is in the spectrum of T. In general, the converse is not true. There are operators on Hilbert or Banach spaces that have no eigenvectors at all. This can be seen in the following example. The bilateral shift on the Hilbert space ℓ 2(Z) (that is, the space of all sequences of scalars … a−1, a0, a1, a2, … such that
converges) has no eigenvalue but does have spectral values.
In infinite-dimensional spaces, the spectrum of a bounded operator is always nonempty. This is also true for an unbounded self adjoint operator. Via its spectral measures, the spectrum of any self adjoint operator, bounded or otherwise, can be decomposed into absolutely continuous, pure point, and singular parts. (See Decomposition of spectrum.)
The hydrogen atom is an example where both types of spectra appear. The eigenfunctions of the hydrogen atom Hamiltonian are called eigenstates and are grouped into two categories. The bound states of the hydrogen atom correspond to the discrete part of the spectrum (they have a discrete set of eigenvalues that can be computed by Rydberg formula) while the ionization processes are described by the continuous part (the energy of the collision/ionization is not quantized).
Eigenfunctions
Main article: EigenfunctionA common example of such maps on infinite dimensional spaces are the action of differential operators on function spaces. As an example, on the space of infinitely differentiable functions, the process of differentiation defines a linear operator since
where f(t) and g(t) are differentiable functions, and a and b are constants.
The eigenvalue equation for linear differential operators is then a set of one or more differential equations. The eigenvectors are commonly called eigenfunctions. The simplest case is the eigenvalue equation for differentiation of a real valued function by a single real variable. We seek a function (equivalent to an infinite-dimensional vector) that, when differentiated, yields a constant times the original function. In this case, the eigenvalue equation becomes the linear differential equation
Here λ is the eigenvalue associated with the function, f(x). This eigenvalue equation has a solution for any value of λ. If λ is zero, the solution is
where A is any constant; if λ is non-zero, the solution is the exponential function
If we expand our horizons to complex valued functions, the value of λ can be any complex number. The spectrum of d/dt is therefore the whole complex plane. This is an example of a continuous spectrum.
Waves on a string
 The shape of a standing wave in a string fixed at its boundaries is an example of an eigenfunction of a differential operator. The admittable eigenvalues are governed by the length of the string and determine the frequency of oscillation.
The shape of a standing wave in a string fixed at its boundaries is an example of an eigenfunction of a differential operator. The admittable eigenvalues are governed by the length of the string and determine the frequency of oscillation.The displacement, h(x,t), of a stressed rope fixed at both ends, like the vibrating strings of a string instrument, satisfies the wave equation
which is a linear partial differential equation, where c is the constant wave speed. The normal method of solving such an equation is separation of variables. If we assume that h can be written as the product of the form X(x)T(t), we can form a pair of ordinary differential equations:
 and
and 
Each of these is an eigenvalue equation (the unfamiliar form of the eigenvalue is chosen merely for convenience). For any values of the eigenvalues, the eigenfunctions are given by
 and
and 
If we impose boundary conditions (that the ends of the string are fixed with X(x) = 0 at x = 0 and x = L, for example) we can constrain the eigenvalues. For those boundary conditions, we find
 , and so the phase angle
, and so the phase angle 
and
Thus, the constant ω is constrained to take one of the values
 , where n is any integer. Thus the clamped string supports a family of standing waves of the form
, where n is any integer. Thus the clamped string supports a family of standing waves of the formFrom the point of view of our musical instrument, the frequency
 is the frequency of the nth harmonic, which is called the (n-1)st overtone.
is the frequency of the nth harmonic, which is called the (n-1)st overtone.Associative algebras and representation theory
Main articles: Representation theory and Weight (representation theory)More algebraically, rather than generalizing the vector space to an infinite dimensional space, one can generalize the algebraic object that is acting on the space, replacing a single operator acting on a vector space with an algebra representation – an associative algebra acting on a module. The study of such actions is the field of representation theory. To understand these representations, one breaks them into indecomposable representations, and, if possible, into irreducible representations; these correspond respectively to generalized eigenspaces and eigenspaces, or rather the indecomposable and irreducible components of these. While a single operator on a vector space can be understood in terms of eigenvectors – 1-dimensional invariant subspaces – in general in representation theory the building blocks (the irreducible representations) are higher-dimensional.
A closer analog of eigenvalues is given by the notion of a weight, with the analogs of eigenvectors and eigenspaces being weight vectors and weight spaces. For an associative algebra A over a field F, the analog of an eigenvalue is a one-dimensional representation
 (a map of algebras; a linear functional that is also multiplicative), called the weight, rather than a single scalar. A map of algebras is used because if a vector is an eigenvector for two elements of an algebra, then it is also an eigenvector for any linear combination of these, and the eigenvalue is the corresponding linear combination of the eigenvalues, and likewise for multiplication. This is related to the classical eigenvalue as follows: a single operator T corresponds to the algebra F[T] (the polynomials in T), and a map of algebras
(a map of algebras; a linear functional that is also multiplicative), called the weight, rather than a single scalar. A map of algebras is used because if a vector is an eigenvector for two elements of an algebra, then it is also an eigenvector for any linear combination of these, and the eigenvalue is the corresponding linear combination of the eigenvalues, and likewise for multiplication. This is related to the classical eigenvalue as follows: a single operator T corresponds to the algebra F[T] (the polynomials in T), and a map of algebras ![\mathbf{F}[T] \to \mathbf{F}](e/1bee3aec97b8042d15d7f9fbf16ee446.png) is determined by its value on the generator T; this value is the eigenvalue. A vector v on which the algebra acts by this weight (i.e., by scalar multiplication, with the scalar determined by the weight) is called a weight vector, and other concepts generalize similarly. The generalization of a diagonalizable matrix (having an eigenbasis) is a weight module.
is determined by its value on the generator T; this value is the eigenvalue. A vector v on which the algebra acts by this weight (i.e., by scalar multiplication, with the scalar determined by the weight) is called a weight vector, and other concepts generalize similarly. The generalization of a diagonalizable matrix (having an eigenbasis) is a weight module.Because a weight is a map to a field, which is commutative, the map factors through the abelianization of the algebra A – equivalently, it vanishes on the derived algebra – in terms of matrices, if v is a common eigenvector of operators T and U, then TUv = UTv (because in both cases it is just multiplication by scalars), so common eigenvectors of an algebra must be in the set on which the algebra acts commutatively (which is annihilated by the derived algebra). Thus of central interest are the free commutative algebras, namely the polynomial algebras. In this particularly simple and important case of the polynomial algebra
![\mathbf{F}[T_1,\dots,T_k]](b/edb4f25a0c6c413d247d3a89f7f61ae6.png) in a set of commuting matrices, a weight vector of this algebra is a simultaneous eigenvector of the matrices, while a weight of this algebra is simply a k-tuple of scalars
in a set of commuting matrices, a weight vector of this algebra is a simultaneous eigenvector of the matrices, while a weight of this algebra is simply a k-tuple of scalars  corresponding to the eigenvalue of each matrix, and hence geometrically to a point in k-space. These weights – in particularly their geometry – are of central importance in understanding the representation theory of Lie algebras, specifically the finite-dimensional representations of semisimple Lie algebras.
corresponding to the eigenvalue of each matrix, and hence geometrically to a point in k-space. These weights – in particularly their geometry – are of central importance in understanding the representation theory of Lie algebras, specifically the finite-dimensional representations of semisimple Lie algebras.As an application of this geometry, given an algebra that is a quotient of a polynomial algebra on k generators, it corresponds geometrically to an algebraic variety in k-dimensional space, and the weight must fall on the variety – i.e., it satisfies defining equations for the variety. This generalizes the fact that eigenvalues satisfy the characteristic polynomial of a matrix in one variable.
Applications
Schrödinger equation
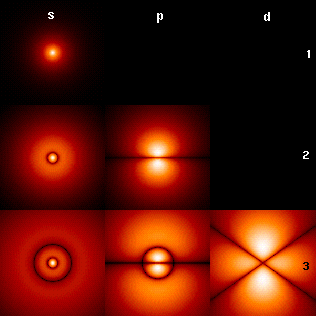
 The wavefunctions associated with the bound states of an electron in a hydrogen atom can be seen as the eigenvectors of the hydrogen atom Hamiltonian as well as of the angular momentum operator. They are associated with eigenvalues interpreted as their energies (increasing downward: n=1,2,3,...) and angular momentum (increasing across: s, p, d,...). The illustration shows the square of the absolute value of the wavefunctions. Brighter areas correspond to higher probability density for a position measurement. The center of each figure is the atomic nucleus, a proton.
The wavefunctions associated with the bound states of an electron in a hydrogen atom can be seen as the eigenvectors of the hydrogen atom Hamiltonian as well as of the angular momentum operator. They are associated with eigenvalues interpreted as their energies (increasing downward: n=1,2,3,...) and angular momentum (increasing across: s, p, d,...). The illustration shows the square of the absolute value of the wavefunctions. Brighter areas correspond to higher probability density for a position measurement. The center of each figure is the atomic nucleus, a proton.An example of an eigenvalue equation where the transformation T is represented in terms of a differential operator is the time-independent Schrödinger equation in quantum mechanics:
where H, the Hamiltonian, is a second-order differential operator and ψE, the wavefunction, is one of its eigenfunctions corresponding to the eigenvalue E, interpreted as its energy.
However, in the case where one is interested only in the bound state solutions of the Schrödinger equation, one looks for ψE within the space of square integrable functions. Since this space is a Hilbert space with a well-defined scalar product, one can introduce a basis set in which ψE and H can be represented as a one-dimensional array and a matrix respectively. This allows one to represent the Schrödinger equation in a matrix form.
Bra-ket notation is often used in this context. A vector, which represents a state of the system, in the Hilbert space of square integrable functions is represented by
 . In this notation, the Schrödinger equation is:
. In this notation, the Schrödinger equation is:where
is an eigenstate of H. It is a self adjoint operator, the infinite dimensional analog of Hermitian matrices (see Observable). As in the matrix case, in the equation above  is understood to be the vector obtained by application of the transformation H to .
is understood to be the vector obtained by application of the transformation H to .Molecular orbitals
In quantum mechanics, and in particular in atomic and molecular physics, within the Hartree–Fock theory, the atomic and molecular orbitals can be defined by the eigenvectors of the Fock operator. The corresponding eigenvalues are interpreted as ionization potentials via Koopmans' theorem. In this case, the term eigenvector is used in a somewhat more general meaning, since the Fock operator is explicitly dependent on the orbitals and their eigenvalues. If one wants to underline this aspect one speaks of nonlinear eigenvalue problem. Such equations are usually solved by an iteration procedure, called in this case self-consistent field method. In quantum chemistry, one often represents the Hartree–Fock equation in a non-orthogonal basis set. This particular representation is a generalized eigenvalue problem called Roothaan equations.
Geology and glaciology
In geology, especially in the study of glacial till, eigenvectors and eigenvalues are used as a method by which a mass of information of a clast fabric's constituents' orientation and dip can be summarized in a 3-D space by six numbers. In the field, a geologist may collect such data for hundreds or thousands of clasts in a soil sample, which can only be compared graphically such as in a Tri-Plot (Sneed and Folk) diagram,[22][23] or as a Stereonet on a Wulff Net.[24] The output for the orientation tensor is in the three orthogonal (perpendicular) axes of space. Eigenvectors output from programs such as Stereo32 [25] are in the order E1 ≥ E2 ≥ E3, with E1 being the primary orientation of clast orientation/dip, E2 being the secondary and E3 being the tertiary, in terms of strength. The clast orientation is defined as the eigenvector, on a compass rose of 360°. Dip is measured as the eigenvalue, the modulus of the tensor: this is valued from 0° (no dip) to 90° (vertical). The relative values of E1, E2, and E3 are dictated by the nature of the sediment's fabric. If E1 = E2 = E3, the fabric is said to be isotropic. If E1 = E2 > E3 the fabric is planar. If E1 > E2 > E3 the fabric is linear. See 'A Practical Guide to the Study of Glacial Sediments' by Benn & Evans, 2004.[26]
Principal components analysis
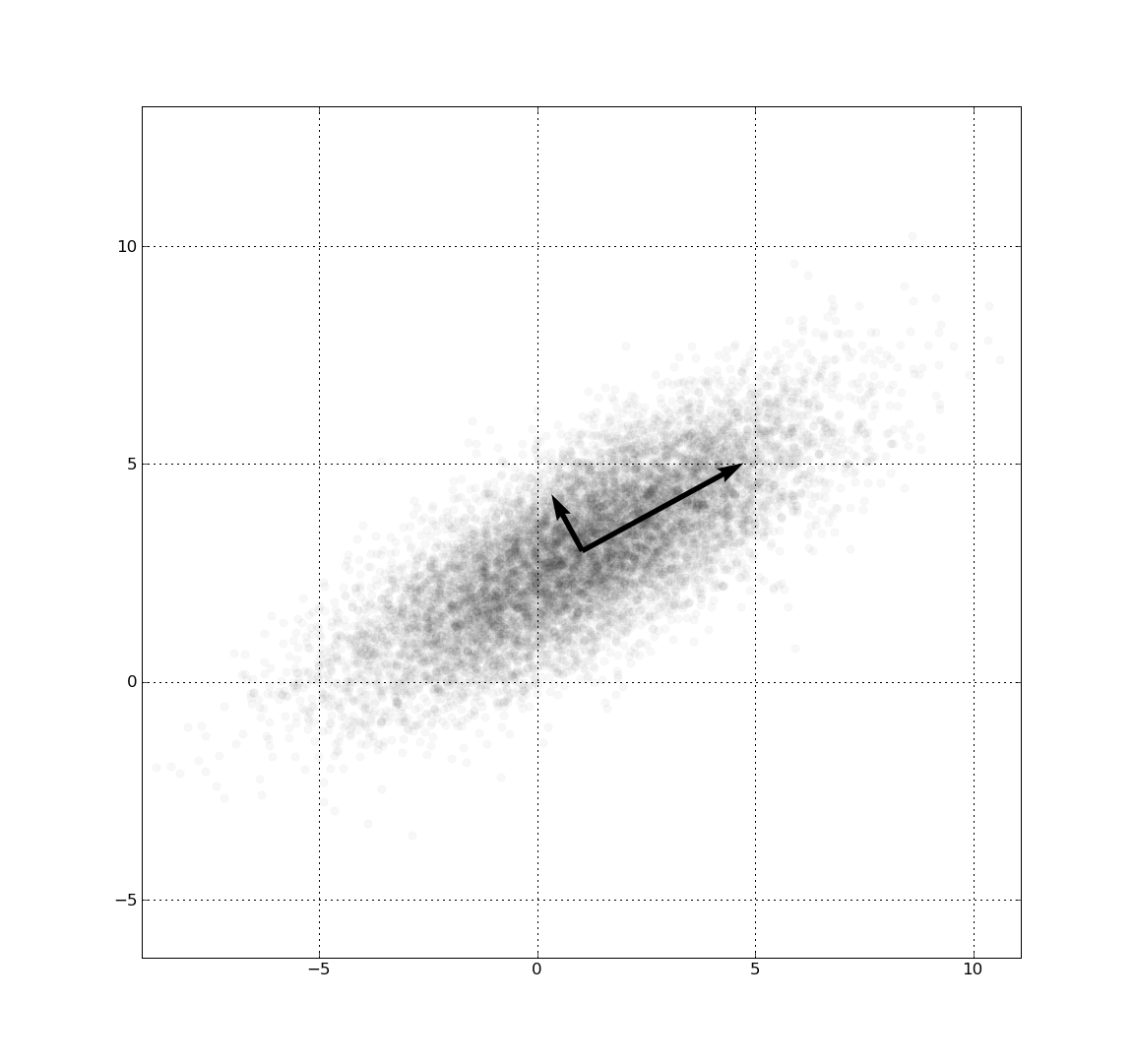
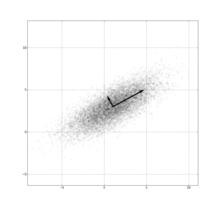 PCA of the multivariate Gaussian distribution centered at (1,3) with a standard deviation of 3 in roughly the (0.878, 0.478) direction and of 1 in the orthogonal direction. The vectors shown are unit eigenvectors of the (symmetric, positive-semidefinite) covariance matrix scaled by the square root of the corresponding eigenvalue. (Just as in the one-dimensional case, the square root is taken because the standard deviation is more readily visualized than the variance.Main article: Principal components analysisSee also: Positive semidefinite matrix and Factor analysis
PCA of the multivariate Gaussian distribution centered at (1,3) with a standard deviation of 3 in roughly the (0.878, 0.478) direction and of 1 in the orthogonal direction. The vectors shown are unit eigenvectors of the (symmetric, positive-semidefinite) covariance matrix scaled by the square root of the corresponding eigenvalue. (Just as in the one-dimensional case, the square root is taken because the standard deviation is more readily visualized than the variance.Main article: Principal components analysisSee also: Positive semidefinite matrix and Factor analysisThe eigendecomposition of a symmetric positive semidefinite (PSD) matrix yields an orthogonal basis of eigenvectors, each of which has a nonnegative eigenvalue. The orthogonal decomposition of a PSD matrix is used in multivariate analysis, where the sample covariance matrices are PSD. This orthogonal decomposition is called principal components analysis (PCA) in statistics. PCA studies linear relations among variables. PCA is performed on the covariance matrix or the correlation matrix (in which each variable is scaled to have its sample variance equal to one). For the covariance or correlation matrix, the eigenvectors correspond to principal components and the eigenvalues to the variance explained by the principal components. Principal component analysis of the correlation matrix provides an orthonormal eigen-basis for the space of the observed data: In this basis, the largest eigenvalues correspond to the principal-components that are associated with most of the covariability among a number of observed data.
Principal component analysis is used to study large data sets, such as those encountered in data mining, chemical research, psychology, and in marketing. PCA is popular especially in psychology, in the field of psychometrics. In Q-methodology, the eigenvalues of the correlation matrix determine the Q-methodologist's judgment of practical significance (which differs from the statistical significance of hypothesis testing): The factors with eigenvalues greater than 1.00 are considered practically significant, that is, as explaining an important amount of the variability in the data, while eigenvalues less than 1.00 are considered practically insignificant, as explaining only a negligible portion of the data variability. More generally, principal component analysis can be used as a method of factor analysis in structural equation modeling.
Vibration analysis
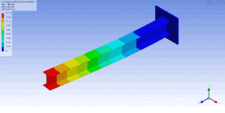 1st lateral bending (See vibration for more types of vibration)Main article: Vibration
1st lateral bending (See vibration for more types of vibration)Main article: VibrationEigenvalue problems occur naturally in the vibration analysis of mechanical structures with many degrees of freedom. The eigenvalues are used to determine the natural frequencies (or eigenfrequencies) of vibration, and the eigenvectors determine the shapes of these vibrational modes. In particular, undamped vibration is governed by
or
that is, acceleration is proportional to position (i.e., we expect x to be sinusoidal in time). In n dimensions, m becomes a mass matrix and k a stiffness matrix. Admissible solutions are then a linear combination of solutions to the generalized eigenvalue problem
- − kx = ω2mx
where ω2 is the eigenvalue and ω is the angular frequency. Note that the principal vibration modes are different from the principal compliance modes, which are the eigenvectors of k alone. Furthermore, damped vibration, governed by
leads to what is called a so-called quadratic eigenvalue problem,
- (ω2m + ωc + k)x = 0.
This can be reduced to a generalized eigenvalue problem by clever algebra at the cost of solving a larger system.
The orthogonality properties of the eigenvectors allows decoupling of the differential equations so that the system can be represented as linear summation of the eigenvectors. The eigenvalue problem of complex structures is often solved using finite element analysis, but neatly generalize the solution to scalar-valued vibration problems.
Eigenfaces
 Eigenfaces as examples of eigenvectorsMain article: Eigenface
Eigenfaces as examples of eigenvectorsMain article: EigenfaceIn image processing, processed images of faces can be seen as vectors whose components are the brightnesses of each pixel.[27] The dimension of this vector space is the number of pixels. The eigenvectors of the covariance matrix associated with a large set of normalized pictures of faces are called eigenfaces; this is an example of principal components analysis. They are very useful for expressing any face image as a linear combination of some of them. In the facial recognition branch of biometrics, eigenfaces provide a means of applying data compression to faces for identification purposes. Research related to eigen vision systems determining hand gestures has also been made.
Similar to this concept, eigenvoices represent the general direction of variability in human pronunciations of a particular utterance, such as a word in a language. Based on a linear combination of such eigenvoices, a new voice pronunciation of the word can be constructed. These concepts have been found useful in automatic speech recognition systems, for speaker adaptation.
Tensor of inertia
In mechanics, the eigenvectors of the inertia tensor define the principal axes of a rigid body. The tensor of inertia is a key quantity required to determine the rotation of a rigid body around its center of mass.
Stress tensor
In solid mechanics, the stress tensor is symmetric and so can be decomposed into a diagonal tensor with the eigenvalues on the diagonal and eigenvectors as a basis. Because it is diagonal, in this orientation, the stress tensor has no shear components; the components it does have are the principal components.
Eigenvalues of a graph
In spectral graph theory, an eigenvalue of a graph is defined as an eigenvalue of the graph's adjacency matrix A, or (increasingly) of the graph's Laplacian matrix (see also Discrete Laplace operator), which is either T−A (sometimes called the Combinatorial Laplacian) or I−T−1/2AT−1/2 (sometimes called the Normalized Laplacian), where T is a diagonal matrix with Tv,v equal to the degree of vertex v, and in T−1/2, the vth diagonal entry is deg(v)−1/2. The kth principal eigenvector of a graph is defined as either the eigenvector corresponding to the kth largest or kth smallest eigenvalue of the Laplacian. The first principal eigenvector of the graph is also referred to merely as the principal eigenvector.
The principal eigenvector is used to measure the centrality of its vertices. An example is Google's PageRank algorithm. The principal eigenvector of a modified adjacency matrix of the World Wide Web graph gives the page ranks as its components. This vector corresponds to the stationary distribution of the Markov chain represented by the row-normalized adjacency matrix; however, the adjacency matrix must first be modified to ensure a stationary distribution exists. The second smallest eigenvector can be used to partition the graph into clusters, via spectral clustering. Other methods are also available for clustering.
Basic reproduction number
The basic reproduction number (R0) is a fundamental number in the study of how infectious diseases spread. If one infectious person is put into a population of completely susceptible people, then R0 is the average number of people that one infectious person will infect. The generation time of an infection is the time, tG, from one person become infected to the next person becoming infected. In a heterogenous population, the next generation matrix defines how many people in the population will become infected after time tG has passed. R0 is then the largest eigenvalue of the next generation matrix. This result is due to Heesterbeek, at the University of Utrecht.[28][29]
See also
- Nonlinear eigenproblem
- Quadratic eigenvalue problem
- Introduction to eigenstates
- Eigenplane
- Jordan normal form
- List of numerical analysis software
Notes
- ^ See also: eigen or eigenvalue at Wiktionary.
- ^ "Eigenvector". Wolfram Research, Inc.. http://mathworld.wolfram.com/Eigenvector.html. Retrieved 29 January 2010.
- ^ See Korn & Korn 2000, Section 14.3.5a; Friedberg, Insel & Spence 1989, p. 217
- ^ Axler, Sheldon, "Ch. 5", Linear Algebra Done Right (2nd ed.), p. 77
- ^ For a proof of this lemma, see Shilov 1977, p. 109, and Lemma for the eigenspace
- ^ For a proof of this lemma, see Roman 2008, Theorem 8.2 on p. 186; Shilov 1977, p. 109; Hefferon 2001, p. 364; Beezer 2006, Theorem EDELI on p. 469; and Lemma for linear independence of eigenvectors
- ^ Strang, Gilbert (1988), Linear Algebra and Its Applications (3rd ed.), San Diego: Harcourt
- ^ Definition according to Weisstein, Eric W. Shear From MathWorld − A Wolfram Web Resource
- ^ a b c d Trefethen, Lloyd N.; Bau, David (1997), Numerical Linear Algebra, SIAM
- ^ LU Householder Transformation
- ^ See Hawkins 1975, §2
- ^ a b c d See Hawkins 1975, §3
- ^ a b c See Kline 1972, pp. 807–808
- ^ See Kline 1972, p. 673
- ^ See Kline 1972, pp. 715–716
- ^ See Kline 1972, pp. 706–707
- ^ See Kline 1972, p. 1063
- ^ See Aldrich 2006
- ^ Francis, J. G. F. (1961), "The QR Transformation, I (part 1)", The Computer Journal 4 (3): 265–271 and Francis, J. G. F. (1962), "The QR Transformation, II (part 2)", The Computer Journal 4 (4): 332–345, doi:10.1093/comjnl/4.4.332
- ^ Kublanovskaya, Vera N. (1961), "On some algorithms for the solution of the complete eigenvalue problem", USSR Computational Mathematics and Mathematical Physics 3: 637–657. Also published in: Zhurnal Vychislitel'noi Matematiki i Matematicheskoi Fiziki 1 (4): 555–570, 1961
- ^ See Golub & van Loan 1996, §7.3; Meyer 2000, §7.3
- ^ Graham, D.; Midgley, N. (2000), "Graphical representation of particle shape using triangular diagrams: an Excel spreadsheet method", Earth Surface Processes and Landforms 25 (13): 1473–1477, doi:10.1002/1096-9837(200012)25:13<1473::AID-ESP158>3.0.CO;2-C
- ^ Sneed, E. D.; Folk, R. L. (1958), "Pebbles in the lower Colorado River, Texas, a study of particle morphogenesis", Journal of Geology 66 (2): 114–150, doi:10.1086/626490
- ^ Knox-Robinson, C (1998), "GIS-stereoplot: an interactive stereonet plotting module for ArcView 3.0 geographic information system", Computers & Geosciences 24 (3): 243, doi:10.1016/S0098-3004(97)00122-2
- ^ Stereo32
- ^ Benn, D.; Evans, D. (2004), A Practical Guide to the study of Glacial Sediments, London: Arnold, pp. 103–107
- ^ Xirouhakis, A.; Votsis, G.; Delopoulus, A. (2004) (PDF), Estimation of 3D motion and structure of human faces, Online paper in PDF format, National Technical University of Athens, http://www.image.ece.ntua.gr/papers/43.pdf
- ^ Diekmann O, Heesterbeek JAP, Metz JAJ (1990). "On the definition and the computation of the basic reproduction ratio R0 in models for infectious diseases in heterogeneous populations". Journal of Mathematical Biology 28 (4): 365–382. PMID 2117040.
- ^ Odo Diekmann and J. A. P. Heesterbeek (2000). Mathematical epidemiology of infectious diseases.. Wiley series in mathematical and computational biology. West Sussex, England: John Wiley & Sons.
References
- Korn, Granino A.; Korn, Theresa M. (2000), Mathematical Handbook for Scientists and Engineers: Definitions, Theorems, and Formulas for Reference and Review, 1152 p., Dover Publications, 2 Revised edition, ISBN 0-486-41147-8.
- Lipschutz, Seymour (1991), Schaum's outline of theory and problems of linear algebra, Schaum's outline series (2nd ed.), New York, NY: McGraw-Hill Companies, ISBN 0-07-038007-4.
- Friedberg, Stephen H.; Insel, Arnold J.; Spence, Lawrence E. (1989), Linear algebra (2nd ed.), Englewood Cliffs, NJ 07632: Prentice Hall, ISBN 0-13-537102-3.
- Aldrich, John (2006), "Eigenvalue, eigenfunction, eigenvector, and related terms", in Jeff Miller (Editor), Earliest Known Uses of Some of the Words of Mathematics, http://jeff560.tripod.com/e.html, retrieved 2006-08-22
- Strang, Gilbert (1993), Introduction to linear algebra, Wellesley-Cambridge Press, Wellesley, MA, ISBN 0-961-40885-5.
- Strang, Gilbert (2006), Linear algebra and its applications, Thomson, Brooks/Cole, Belmont, CA, ISBN 0-030-10567-6.
- Bowen, Ray M.; Wang, Chao-Cheng (1980), Linear and multilinear algebra, Plenum Press, New York, NY, ISBN 0-306-37508-7.
- Cohen-Tannoudji, Claude (1977), "Chapter II. The mathematical tools of quantum mechanics", Quantum mechanics, John Wiley & Sons, ISBN 0-471-16432-1.
- Fraleigh, John B.; Beauregard, Raymond A. (1995), Linear algebra (3rd ed.), Addison-Wesley Publishing Company, ISBN 0-201-83999-7 (international edition).
- Golub, Gene H.; Van Loan, Charles F. (1996), Matrix computations (3rd Edition), Johns Hopkins University Press, Baltimore, MD, ISBN 978-0-8018-5414-9.
- Hawkins, T. (1975), "Cauchy and the spectral theory of matrices", Historia Mathematica 2: 1–29, doi:10.1016/0315-0860(75)90032-4.
- Horn, Roger A.; Johnson, Charles F. (1985), Matrix analysis, Cambridge University Press, ISBN 0-521-30586-1 (hardback), ISBN 0-521-38632-2 (paperback).
- Kline, Morris (1972), Mathematical thought from ancient to modern times, Oxford University Press, ISBN 0-195-01496-0.
- Meyer, Carl D. (2000), Matrix analysis and applied linear algebra, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, ISBN 978-0-89871-454-8.
- Brown, Maureen (October 2004), Illuminating Patterns of Perception: An Overview of Q Methodology.
- Golub, Gene F.; van der Vorst, Henk A. (2000), "Eigenvalue computation in the 20th century", Journal of Computational and Applied Mathematics 123: 35–65, doi:10.1016/S0377-0427(00)00413-1.
- Akivis, Max A.; Vladislav V. Goldberg (1969), Tensor calculus, Russian, Science Publishers, Moscow.
- Gelfand, I. M. (1971), Lecture notes in linear algebra, Russian, Science Publishers, Moscow.
- Alexandrov, Pavel S. (1968), Lecture notes in analytical geometry, Russian, Science Publishers, Moscow.
- Carter, Tamara A.; Tapia, Richard A.; Papaconstantinou, Anne, Linear Algebra: An Introduction to Linear Algebra for Pre-Calculus Students, Rice University, Online Edition, http://ceee.rice.edu/Books/LA/index.html, retrieved 2008-02-19.
- Roman, Steven (2008), Advanced linear algebra (3rd ed.), New York, NY: Springer Science + Business Media, LLC, ISBN 978-0-387-72828-5.
- Shilov, Georgi E. (1977), Linear algebra (translated and edited by Richard A. Silverman ed.), New York: Dover Publications, ISBN 0-486-63518-X.
- Hefferon, Jim (2001), Linear Algebra, Online book, St Michael's College, Colchester, Vermont, USA, http://joshua.smcvt.edu/linearalgebra/.
- Kuttler, Kenneth (2007) (PDF), An introduction to linear algebra, Online e-book in PDF format, Brigham Young University, http://www.math.byu.edu/~klkuttle/Linearalgebra.pdf.
- Demmel, James W. (1997), Applied numerical linear algebra, SIAM, ISBN 0-89871-389-7.
- Beezer, Robert A. (2006), A first course in linear algebra, Free online book under GNU licence, University of Puget Sound, http://linear.ups.edu/.
- Lancaster, P. (1973), Matrix theory, Russian, Moscow, Russia: Science Publishers.
- Halmos, Paul R. (1987), Finite-dimensional vector spaces (8th ed.), New York, NY: Springer-Verlag, ISBN 0387900934.
- Pigolkina, T. S. and Shulman, V. S., Eigenvalue (in Russian), In:Vinogradov, I. M. (Ed.), Mathematical Encyclopedia, Vol. 5, Soviet Encyclopedia, Moscow, 1977.
- Greub, Werner H. (1975), Linear Algebra (4th Edition), Springer-Verlag, New York, NY, ISBN 0-387-90110-8.
- Larson, Ron; Edwards, Bruce H. (2003), Elementary linear algebra (5th ed.), Houghton Mifflin Company, ISBN 0-618-33567-6.
- Curtis, Charles W., Linear Algebra: An Introductory Approach, 347 p., Springer; 4th ed. 1984. Corr. 7th printing edition (August 19, 1999), ISBN 0-387-90992-3.
- Shores, Thomas S. (2007), Applied linear algebra and matrix analysis, Springer Science+Business Media, LLC, ISBN 0-387-33194-8.
- Sharipov, Ruslan A. (1996), Course of Linear Algebra and Multidimensional Geometry: the textbook, arXiv:math/0405323, ISBN 5-7477-0099-5.
- Gohberg, Israel; Lancaster, Peter; Rodman, Leiba (2005), Indefinite linear algebra and applications, Basel-Boston-Berlin: Birkhäuser Verlag, ISBN 3-7643-7349-0.
External links
- What are Eigen Values? — non-technical introduction from PhysLink.com's "Ask the Experts"
- Eigen Values and Eigen Vectors Numerical Examples – Tutorial and Interactive Program from Revoledu.
- Introduction to Eigen Vectors and Eigen Values – lecture from Khan Academy
Theory
- Eigenvalue (of a matrix) on PlanetMath
- Eigenvector — Wolfram MathWorld
- Eigen Vector Examination working applet
- Same Eigen Vector Examination as above in a Flash demo with sound
- Computation of Eigenvalues
- Numerical solution of eigenvalue problems Edited by Zhaojun Bai, James Demmel, Jack Dongarra, Axel Ruhe, and Henk van der Vorst
- Eigenvalues and Eigenvectors on the Ask Dr. Math forums: [1], [2]
Online calculators
Topics related to linear algebra Scalar · Vector · Vector space · Vector projection · Linear span · Linear map · Linear projection · Linear independence · Linear combination · Basis · Column space · Row space · Dual space · Orthogonality · Rank · Minor · Kernel · Eigenvalues and eigenvectors · Least squares regressions · Outer product · Inner product space · Dot product · Transpose · Gram–Schmidt process · Matrix decompositionAreas of mathematics Areas Arithmetic · Algebra (elementary – linear – multilinear – abstract) · Geometry (Discrete geometry – Algebraic geometry – Differential geometry) · Calculus/Analysis · Set theory · Logic · Category theory · Number theory · Combinatorics · Graph theory · Topology · Lie theory · Differential equations/Dynamical systems · Mathematical physics · Numerical analysis · Computation · Information theory · Probability · Statistics · Optimization · Control theory · Game theory
Divisions Category · Mathematics portal · Outline · Lists Categories:- Featured articles on Mathematics Portal
- Fundamental physics concepts
- Abstract algebra
- Linear algebra
- Matrices
- Singular value decomposition
- German words and phrases
- German loanwords














































Wikimedia Foundation. 2010.